デバッグをしよう
デバッグとは
デバッグとはバグを取り除く事です。時には何度も実行して動作に異常がないか確認をしたり、時にはソースを眺めたりして、不具合をどんどん消していきます。
昔「ジーンダイバー」というアニメの中で、パックというキャラが、人類を地球の歴史から消し去ろうとしている敵(プグラシュティク)に対し、 コンピューターに侵入し、わざとバグを付け加えるという攻撃をします。 その際に敵の1人、バン・ニーというキャラが言いました。「やはりデ↑バッグが甘かったか」と。(「デバッグ」のアクセントがちょっと気になりましたが・・・。デ→バ→ッグ→(平坦読み)ですので、念のため)
デバッグは重要です。というより、デバッグなしのプログラムはまず動きません。どんなプログラムでも、ソースを眺めたところで実際に走らせてみないことには、どういう動作をするのか人間の頭では追いきれません。また、完璧に文法通りに作ったとしても言語のランタイムの方にバグがある場合もありますし、ヘタをするとデーターベースやOS側にバグがあってうまく動かないかもしれません。
という事でプログラムはまず走らせてみる、これは基本中の基本です。プログラムを何度も走らせてバグがないかどうか確認したり、わざと通常とは違う操作をして致命的なエラーが出ないかどうかを確認する事をランニングデバッキングといいます。
昔「ジーンダイバー」というアニメの中で、パックというキャラが、人類を地球の歴史から消し去ろうとしている敵(プグラシュティク)に対し、 コンピューターに侵入し、わざとバグを付け加えるという攻撃をします。 その際に敵の1人、バン・ニーというキャラが言いました。「やはりデ↑バッグが甘かったか」と。(「デバッグ」のアクセントがちょっと気になりましたが・・・。デ→バ→ッグ→(平坦読み)ですので、念のため)
デバッグは重要です。というより、デバッグなしのプログラムはまず動きません。どんなプログラムでも、ソースを眺めたところで実際に走らせてみないことには、どういう動作をするのか人間の頭では追いきれません。また、完璧に文法通りに作ったとしても言語のランタイムの方にバグがある場合もありますし、ヘタをするとデーターベースやOS側にバグがあってうまく動かないかもしれません。
という事でプログラムはまず走らせてみる、これは基本中の基本です。プログラムを何度も走らせてバグがないかどうか確認したり、わざと通常とは違う操作をして致命的なエラーが出ないかどうかを確認する事をランニングデバッキングといいます。
ランニングデバッキング
文字通り、走らせてデバッグをする事です。初めて走らせるプログラムは、1回目は大抵文法エラーになります(って私だけ??)文法違反ならエラーを発してくれるから良いのですが、エラーにならないバグは困ります。数値が希望通りになってなかったり、入力したハズのデーターがDBに登録されなかったり、表示が途中切れになってしまったり、印字が枠をはみ出てしまったり・・・。
発生頻度100%なら良いのですが、条件が重なった場合にしか通らない所にバグがあると、発見はさらに困難になります。ある条件が重なると、数値が少しだけ違ってしまうとか。
そこで、ランニングデバッキングをする際に気をつけなければならない事をいくつか挙げていきましょう。
発生頻度100%なら良いのですが、条件が重なった場合にしか通らない所にバグがあると、発見はさらに困難になります。ある条件が重なると、数値が少しだけ違ってしまうとか。
そこで、ランニングデバッキングをする際に気をつけなければならない事をいくつか挙げていきましょう。
通常ではしない操作をしてみる
MS-DOSの頃と違いGUI操作では使わないキーを押しても、大抵は何も受け付けないので、変なキーを押すとファイルが破損するといった最悪の事態は想定しなくとも良いのですが、異常な値を入れた場合に対する対策は必要です。
例えば、数値タイプを入れて欲しい項目に、aとか入れるとエラーになる・・・のならともかく、PHPなど0として解釈してしまう言語もあるでしょうから、数値タイプの入力欄に数字以外が入れられた時にどう動くかは検証しておきます。数値入力の枠はVBならプロパティで、PHPならIME-MODEの指定で半角しか入力できなくする方が良いでしょう。
数値入力であっても、1111111111111111111111111111111111111111みたいな通常では考えれない数値が入れられた際に、
・そのまま精度を上げて計算する
・直後にエラーメッセージを出す
となっていれば良いのですが、そこではそのままエラーメッセージを出さずにDBに記録され、別の売上げ金額などを集計する所でエラーになるような仕様だと、何が原因でエラーが出てるのか発見が困難になります。不正なデーターは、最初から入らないように入力チェックを入れるべきでしょう。
日付の入力は、プログラムを作る側の人間は暗黙に「存在しない日は入れない」というルール(?)があって、ついデバッグから漏れてしまうのですが、エンドユーザーが誤って入れてしまうケースはよくあります。日付を入力させる際に2001年2月29日という存在しない日付を入れるとデーターベースにinsertする時にエラーが出てしまいます。データーベースのエラーメッセージは英文字であまりエンドユーザーに直接見せて良いものではありませんし、データーベースのエラーが発生した際に「エラーが発生しました。申し訳ありませんが管理者に連絡してください」と表示されるにしても、そこで苦情電話がかかってくるでしょう。日付は入力画面の次の画面で存在をチェックし、存在しない日付ならそこでちゃんとしたエンドユーザー向けのエラーメッセージを出すべきです。
PHPでは特に気にしなければならないのが、ブラウザの「戻る」と「リロード」です。「戻る」「リロード」はプログラムを作る側としては押して欲しくないキーですが、回線が重かったり、操作をする人が途中で間違いに気づいた時にはまず押すでしょう。戻る→登録→戻る→登録を繰り返したときに、同じ情報が多重に登録されないようにしなければなりません。POST直後の「リロード」でも同様です。insert文でキーのデュプリケートエラーが画面に出てしまうのもカッコ悪いので、PHP側で同じデーターを繰り返し送信されてきたのかをチェックする必要があると思います。
例えば、数値タイプを入れて欲しい項目に、aとか入れるとエラーになる・・・のならともかく、PHPなど0として解釈してしまう言語もあるでしょうから、数値タイプの入力欄に数字以外が入れられた時にどう動くかは検証しておきます。数値入力の枠はVBならプロパティで、PHPならIME-MODEの指定で半角しか入力できなくする方が良いでしょう。
数値入力であっても、1111111111111111111111111111111111111111みたいな通常では考えれない数値が入れられた際に、
・そのまま精度を上げて計算する
・直後にエラーメッセージを出す
となっていれば良いのですが、そこではそのままエラーメッセージを出さずにDBに記録され、別の売上げ金額などを集計する所でエラーになるような仕様だと、何が原因でエラーが出てるのか発見が困難になります。不正なデーターは、最初から入らないように入力チェックを入れるべきでしょう。
日付の入力は、プログラムを作る側の人間は暗黙に「存在しない日は入れない」というルール(?)があって、ついデバッグから漏れてしまうのですが、エンドユーザーが誤って入れてしまうケースはよくあります。日付を入力させる際に2001年2月29日という存在しない日付を入れるとデーターベースにinsertする時にエラーが出てしまいます。データーベースのエラーメッセージは英文字であまりエンドユーザーに直接見せて良いものではありませんし、データーベースのエラーが発生した際に「エラーが発生しました。申し訳ありませんが管理者に連絡してください」と表示されるにしても、そこで苦情電話がかかってくるでしょう。日付は入力画面の次の画面で存在をチェックし、存在しない日付ならそこでちゃんとしたエンドユーザー向けのエラーメッセージを出すべきです。
PHPでは特に気にしなければならないのが、ブラウザの「戻る」と「リロード」です。「戻る」「リロード」はプログラムを作る側としては押して欲しくないキーですが、回線が重かったり、操作をする人が途中で間違いに気づいた時にはまず押すでしょう。戻る→登録→戻る→登録を繰り返したときに、同じ情報が多重に登録されないようにしなければなりません。POST直後の「リロード」でも同様です。insert文でキーのデュプリケートエラーが画面に出てしまうのもカッコ悪いので、PHP側で同じデーターを繰り返し送信されてきたのかをチェックする必要があると思います。
0であるはずのデーターが0、というのは正解ではない
これもよくやってしまう間違いなのですが、たとえばみかんの売上げ、りんごの売上げ、バナナの売上げを集計して月毎に表示するプログラムがあったとします。
ある人はこのようにデバッグしました。
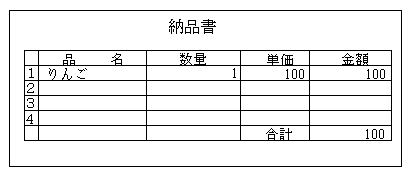
リンゴを1個売りました。100円でした。

月別売上げで100円が出ました。デバッグ終了です。「いや~終わった終わった・・。ではお先に失礼します」
・・・って、ちょっと待ってください
この場合、デバッグとしてはいくつか問題があります。
・伝票で1行しか入力しておらず合計金額が合わないバグがあっても見つけられない
・リンゴの売上げしかないので、みかんやバナナの売上げがリストに反映されないというバグがあっても見つけられない
・3月の売上げしかなく、4月5月の売上げがリストに反映されないというバグがあっても見つけられない
売上げが反映されないバグとしては、データーベースにinsertする際の変数名間違え、データーベースから出す際の変数名間違い、データーベースからselectするフィールドリストに入れ忘れ、表示する際の変数名間違えなど、色々な可能性があります。
ゼロという数値は、プログラムが間違っている場合でもよく発生する値です。特に変数の宣言を必要としない言語では、代入時に間違えたとしてもそのままゼロとして扱われるため、バグの発見を遅らせます。
という事で、全ての行が入った伝票や、1行だけ、2行だけといった複数枚の伝票を入力し、品物も全部は無理としてもできる限り多くの品目を入力してテストします。当然、商品コードとして存在しないコードを入れた場合にどうなるかもテストします。また、集計表には3桁ごとにカンマが入ると思いますが、本当にカンマが出るかも確認します。
ある人はこのようにデバッグしました。
リンゴを1個売りました。100円でした。
月別売上げで100円が出ました。デバッグ終了です。「いや~終わった終わった・・。ではお先に失礼します」
・・・って、ちょっと待ってください
この場合、デバッグとしてはいくつか問題があります。
・伝票で1行しか入力しておらず合計金額が合わないバグがあっても見つけられない
・リンゴの売上げしかないので、みかんやバナナの売上げがリストに反映されないというバグがあっても見つけられない
・3月の売上げしかなく、4月5月の売上げがリストに反映されないというバグがあっても見つけられない
売上げが反映されないバグとしては、データーベースにinsertする際の変数名間違え、データーベースから出す際の変数名間違い、データーベースからselectするフィールドリストに入れ忘れ、表示する際の変数名間違えなど、色々な可能性があります。
ゼロという数値は、プログラムが間違っている場合でもよく発生する値です。特に変数の宣言を必要としない言語では、代入時に間違えたとしてもそのままゼロとして扱われるため、バグの発見を遅らせます。
という事で、全ての行が入った伝票や、1行だけ、2行だけといった複数枚の伝票を入力し、品物も全部は無理としてもできる限り多くの品目を入力してテストします。当然、商品コードとして存在しないコードを入れた場合にどうなるかもテストします。また、集計表には3桁ごとにカンマが入ると思いますが、本当にカンマが出るかも確認します。
リアルな値を入れてみる
ある人がこのようにデバッグしました
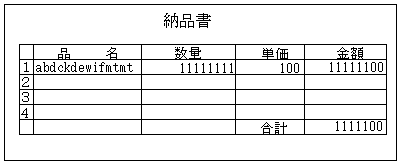
デバッグ終了です。「いや~終わった終わった・・。ではお先に失礼します」
・・・って、ちょっと待ってください
このデバッグにも色々と問題があります。
まず、商品名abdckdewifmtmtが妥当かどうかわかりません。つまり、データーベースから商品名を出す際に正しい商品名が出てきてるのか、文字コードを間違えて文字化けしてしまうというバグがあるかどうかわかりません。商品名が何文字目かで欠落してしまうというバグがあってもわかりません。
上の例では、合計金額が桁あふれを起こして1桁落ちてしまっていますが、11111…というあまり意味のない数が表示されていては見落としてしまいがちです。あまりリアルではい値が出てると、とにかく「それっぽい値が出てる」と脳内変換を起こしてしまうと思います。
また、上の例では品名が左に寄りすぎ、数量が右に寄りすぎです。しかし、表示されている文字数(桁数)がリアルな値ではないため、一見しても気づきません。これが「りんご」「1」とリアルな数にしてみると、表示位置が寄りすぎなのがわかると思います。
また、IME-MODEの指定忘れ等の操作性の問題があったとしても、デバッグする側が自分が本当にその業務で使うつもりで使わずに、てきとーにキーを連打していただけでは気づかないと思います。
というように、デバッグする際にはそこにどんな値がどんな桁数、どんな文字列長で入るかを調べ、実際に近い値を入れてみてテストしましょう。
デバッグ終了です。「いや~終わった終わった・・。ではお先に失礼します」
・・・って、ちょっと待ってください
このデバッグにも色々と問題があります。
まず、商品名abdckdewifmtmtが妥当かどうかわかりません。つまり、データーベースから商品名を出す際に正しい商品名が出てきてるのか、文字コードを間違えて文字化けしてしまうというバグがあるかどうかわかりません。商品名が何文字目かで欠落してしまうというバグがあってもわかりません。
上の例では、合計金額が桁あふれを起こして1桁落ちてしまっていますが、11111…というあまり意味のない数が表示されていては見落としてしまいがちです。あまりリアルではい値が出てると、とにかく「それっぽい値が出てる」と脳内変換を起こしてしまうと思います。
また、上の例では品名が左に寄りすぎ、数量が右に寄りすぎです。しかし、表示されている文字数(桁数)がリアルな値ではないため、一見しても気づきません。これが「りんご」「1」とリアルな数にしてみると、表示位置が寄りすぎなのがわかると思います。
また、IME-MODEの指定忘れ等の操作性の問題があったとしても、デバッグする側が自分が本当にその業務で使うつもりで使わずに、てきとーにキーを連打していただけでは気づかないと思います。
というように、デバッグする際にはそこにどんな値がどんな桁数、どんな文字列長で入るかを調べ、実際に近い値を入れてみてテストしましょう。
ペーパーデバッキング
ランニングデバッキングをしなければ、変数名間違いなどは発見しにくいです。特に、プログラムを作った本人は脳内変換を起こしてしまいます。$mark2という変数を使うつもりで$merk2と入れてしまっても、プログラムを作った本人は「$mark2」と脳内変換してしまい、バグに気づきません。
という事で大切なランニングデバッキングですが、ランニングでは気づかないバグもあります。再現率が少ないバグです。
例えば、リロードボタンを押した時はテーブルにinsertせずにupdateするつもりで作ったプログラムが、バグでリロードしてもinsertしてしまうアルゴリズムになっていたとします。プログラムの最初の方で前回入力されたキーと同じキーが送信されたた$new_flgという変数が1になるものとして、以下の場合
という事で大切なランニングデバッキングですが、ランニングでは気づかないバグもあります。再現率が少ないバグです。
例えば、リロードボタンを押した時はテーブルにinsertせずにupdateするつもりで作ったプログラムが、バグでリロードしてもinsertしてしまうアルゴリズムになっていたとします。プログラムの最初の方で前回入力されたキーと同じキーが送信されたた$new_flgという変数が1になるものとして、以下の場合
例)
if ($new_flg=1){
$sql="insert into shohin (hincode, hinmei,tanka,irisuu)values('1',
'りんご,'100','1')";
}else{
$sql="update shohin set hinmei='りんご', tanka='100', irisuu='1' where
hincode='1'";
}
$result=pg_query($sql);
【解説】
ここで、==を=と間違えて書いてしまったために偽とはならず、何度リロードしてもリンゴがinsertされてしまう。
確かにランニングデバッキング中にリロードボタンを押せば発見できますが、それは結果論であって、数ある同様の処理の中に1つだけこのようなミスがあったとして、そこまで全部試せきれない事がほとんどです。というように、ランニングで全てのバグが取れるわけではありません。
こういう事があるので、ランニングだけでなく、完成リストも何度も見直します。特にifの()内には注意して見直しましょう。ここでは説明用に単純な条件判断にしましたが、実際にはif else の関係やwhile break continueの関係がもっともっと複雑になってきます。どこのbreakがどのループを抜けるのか一見してわからない事も多く、特にループの範囲が広く画面からスクロールアウトしてしまう場合は発見が困難です。
こういう時はペーパーデバッキングをします。ペーパーデバッキングとは、ソースをプリントしてデバッグする事です。紙は、画面と違いさまざまなメリットがあります。
・自分の好きなように余白に書き込める
・好きなように蛍光ペンを塗れる
・1画面に収まらない範囲のソースを一見できる
余白に自由に書き込めるのはかなりのメリットです。whileとbreakや、ifとelseの関係を鉛筆で線で結んだり丸をつけたり、メモ書きをしたり、対になるwhileとcontinueやbreakをそれぞれ異なる色の蛍光ペンで塗ったりでき、画面で見ただけでは発見が困難なバグを発見しやすくなります。
こういう事があるので、ランニングだけでなく、完成リストも何度も見直します。特にifの()内には注意して見直しましょう。ここでは説明用に単純な条件判断にしましたが、実際にはif else の関係やwhile break continueの関係がもっともっと複雑になってきます。どこのbreakがどのループを抜けるのか一見してわからない事も多く、特にループの範囲が広く画面からスクロールアウトしてしまう場合は発見が困難です。
こういう時はペーパーデバッキングをします。ペーパーデバッキングとは、ソースをプリントしてデバッグする事です。紙は、画面と違いさまざまなメリットがあります。
・自分の好きなように余白に書き込める
・好きなように蛍光ペンを塗れる
・1画面に収まらない範囲のソースを一見できる
余白に自由に書き込めるのはかなりのメリットです。whileとbreakや、ifとelseの関係を鉛筆で線で結んだり丸をつけたり、メモ書きをしたり、対になるwhileとcontinueやbreakをそれぞれ異なる色の蛍光ペンで塗ったりでき、画面で見ただけでは発見が困難なバグを発見しやすくなります。
最後の手段!?
どうしてもバグが発見できない時は、最後の手段としてドットプリンターを使うという手もあります。ドットプリンターは今ではめったに使われないばかりか、今もそれがある会社は珍しいのですが、ドットプリンターで使う事のできる連続帳票はペーパーデバッキングの強い味方となります。

連続帳票ならばループの途中で改ページしてしまって見づらくなってしまう事がないため、長く複雑なループや条件文の処理を把握するのに威力を発揮します。ドットプリンターがない場合は、とりあえずページプリンターで印刷した後、1つの関数の範囲分のりやセロテープでくっつけるという手もあります。そして、怪しい箇所には蛍光ペンを塗っていきます。
どんなに技術が進化しても、最終的に頼りになるのは、ドットインパクトプリンタ+連続帳票+蛍光ペンといった、極めて原始的な手段なのかもしれません。
どうしてもバグが発見できない時は、最後の手段としてドットプリンターを使うという手もあります。ドットプリンターは今ではめったに使われないばかりか、今もそれがある会社は珍しいのですが、ドットプリンターで使う事のできる連続帳票はペーパーデバッキングの強い味方となります。
連続帳票ならばループの途中で改ページしてしまって見づらくなってしまう事がないため、長く複雑なループや条件文の処理を把握するのに威力を発揮します。ドットプリンターがない場合は、とりあえずページプリンターで印刷した後、1つの関数の範囲分のりやセロテープでくっつけるという手もあります。そして、怪しい箇所には蛍光ペンを塗っていきます。
どんなに技術が進化しても、最終的に頼りになるのは、ドットインパクトプリンタ+連続帳票+蛍光ペンといった、極めて原始的な手段なのかもしれません。
変数の値を表示する
変数に宣言を必要としない言語でよくやる失敗が変数名間違いです。というか、高レベル言語は変数名間違いとの戦いといってもいいでしょう。(って自分だけ??)
Perlでは、最初の方でuse strictを宣言する事で、変数の宣言を必須にできます。これにより、変数名間違いがエラーとなり、発見しやすくなります。(宣言済みの別の変数と間違えるとだめですが。)VisualBasicでもOption Explicitを宣言すれば、変数の宣言が必須となります。
PHPでは変数の宣言が(この文を書いてる時点のバージョンでは)できません。なので、変数名を間違えると新しい変数とみなされ、代入してるはずの変数に代入されてなかった、という事がしばしば発生します。この場合、ViViなどのエディタで検索文字列を色を変えて表示させるという手もありますが、どうしても思い通りに動いてくれないという時は、デバッグ用として各所で変数の中身を表示させるようにします。
Perlでは、最初の方でuse strictを宣言する事で、変数の宣言を必須にできます。これにより、変数名間違いがエラーとなり、発見しやすくなります。(宣言済みの別の変数と間違えるとだめですが。)VisualBasicでもOption Explicitを宣言すれば、変数の宣言が必須となります。
PHPでは変数の宣言が(この文を書いてる時点のバージョンでは)できません。なので、変数名を間違えると新しい変数とみなされ、代入してるはずの変数に代入されてなかった、という事がしばしば発生します。この場合、ViViなどのエディタで検索文字列を色を変えて表示させるという手もありますが、どうしても思い通りに動いてくれないという時は、デバッグ用として各所で変数の中身を表示させるようにします。
例)
//debug
printf("\$aaa=[%s]<br>",$aaa);
「あれ?」とか「そんなバカな」と思った所に変数の中身を表示する仕掛けを入れておきます。<br>はPHP用で、ブラウザに表示させた時に改行になります。よくあるのがsqlのステートメントを表示させてみることです。特にinsert、updateのようなステートメントを動的に生成する箇所などは、うまく動かない場合だけでなく、最初の1回目はsqlを表示させて確認してみると良いでしょう。
プログラムが思い通りに動いたらデバッグ表示を消しますが、削除するのではなくprintfの手前に//を入れてコメントアウトします。こうする事で、再び動作不具合が発生した際に簡単に変数表示に戻すことができます。また、デバッグ用表示には//debugというようなデバッグ用表示に共通したキーワードを入れておき、エディタの検索機能で外し忘れを発見できるようにしておきます。
プログラムが思い通りに動いたらデバッグ表示を消しますが、削除するのではなくprintfの手前に//を入れてコメントアウトします。こうする事で、再び動作不具合が発生した際に簡単に変数表示に戻すことができます。また、デバッグ用表示には//debugというようなデバッグ用表示に共通したキーワードを入れておき、エディタの検索機能で外し忘れを発見できるようにしておきます。
デバッグモード
変数の値を表示する箇所をコメントアウトしたとたんにバグが発生し、コメントアウトを解除してすぐに盆ミスに気づいて後悔し、再びコメントアウトしたとたん別の不具合が発生し・・・という事がよくあると思います。(って私だけ?)
こういう時は、デバッグモードという隠し機能をつけておきます。CやPerl等で特定のオプションをつけて起動したらデバッグモードになるとか、PHPであればURLの最後に、?debug=1とか入れるととデバッグモードになる、とかです。また、デバッグモードの存在はエンドユーザーには(というか自分以外の人間には?)知られないようにしておきます。
こうする事で、不具合が発覚したらデバッグモードで検証するという事ができます。デバッグモードでは途中で変数値を表示させたりします。また、通販サイトのデバッグモードであれば、同じ商品を何度も何度も、売上げ金額への計上や在庫の引き落としをせずに行う事ができるようにします。
昔の8ビット機時代のゲームは、デバッグモードが残っているものが多かったです。あるキーとあるキーを押すと無条件で次の面に進めたり、自機を増やせたり、無敵モードにできたり・・・という機能が市販の状態でも残ってたりしました。また、それがパソコン雑誌とかで取り上げられて裏ワザとして紹介されたりしました。
気をつけなければならないのは、デバッグモードは完成段階では外さなければならないという事です。ゲームならば裏ワザで済みますが、通販サイトでは大変な事になります。もし0円で物が購入できる裏ワザなんて残っていたら、それこそ売る側は破産ですし、sqlを表示させるワザが残っていたらインジェクションしてくださいと言ってるようなものです。
こういう時は、デバッグモードという隠し機能をつけておきます。CやPerl等で特定のオプションをつけて起動したらデバッグモードになるとか、PHPであればURLの最後に、?debug=1とか入れるととデバッグモードになる、とかです。また、デバッグモードの存在はエンドユーザーには(というか自分以外の人間には?)知られないようにしておきます。
こうする事で、不具合が発覚したらデバッグモードで検証するという事ができます。デバッグモードでは途中で変数値を表示させたりします。また、通販サイトのデバッグモードであれば、同じ商品を何度も何度も、売上げ金額への計上や在庫の引き落としをせずに行う事ができるようにします。
昔の8ビット機時代のゲームは、デバッグモードが残っているものが多かったです。あるキーとあるキーを押すと無条件で次の面に進めたり、自機を増やせたり、無敵モードにできたり・・・という機能が市販の状態でも残ってたりしました。また、それがパソコン雑誌とかで取り上げられて裏ワザとして紹介されたりしました。
気をつけなければならないのは、デバッグモードは完成段階では外さなければならないという事です。ゲームならば裏ワザで済みますが、通販サイトでは大変な事になります。もし0円で物が購入できる裏ワザなんて残っていたら、それこそ売る側は破産ですし、sqlを表示させるワザが残っていたらインジェクションしてくださいと言ってるようなものです。
関数単位で確認
C系の言語(C、C++、Perl、PHPなど)では、プログラムを関数単位で作ってゆき、最後に結合すると思います。なので、デバッグは関数単位で行うとと効率が良くなります。
例えば、消費税を計算する関数・・・つまり、データーベースから税率と丸め区分(切捨てとか四捨五入とか)をselectした後、引数から消費税を算出してリターンコードとして消費税額を返す関数があったとします。
この場合、丸めがうまくいってるかどうかチェックするために、その関数に消費税が xx.4円になる、xx.5円になる、xx.6円になる値をそれぞれ与えてみます。これを結合した状態でのテストだけだと、商品コード・商品名・数量・単価・金額と入れて、ちょうどその金額になる状態を作る・・・・なんて手間がかかってしまうし、それが面倒臭くなってそのテストをやったつもりでパスしてしまうケースもままあります。
なので、ピンポイントで何度も何度もその関数が全ての条件を満たすかどうかテストします。そうする事でその関数の信頼性は高まり、別の箇所で使いまわしたとしてもバグの可能性はグンと低くなります。
例えば、消費税を計算する関数・・・つまり、データーベースから税率と丸め区分(切捨てとか四捨五入とか)をselectした後、引数から消費税を算出してリターンコードとして消費税額を返す関数があったとします。
この場合、丸めがうまくいってるかどうかチェックするために、その関数に消費税が xx.4円になる、xx.5円になる、xx.6円になる値をそれぞれ与えてみます。これを結合した状態でのテストだけだと、商品コード・商品名・数量・単価・金額と入れて、ちょうどその金額になる状態を作る・・・・なんて手間がかかってしまうし、それが面倒臭くなってそのテストをやったつもりでパスしてしまうケースもままあります。
なので、ピンポイントで何度も何度もその関数が全ての条件を満たすかどうかテストします。そうする事でその関数の信頼性は高まり、別の箇所で使いまわしたとしてもバグの可能性はグンと低くなります。
中間法
関数単位でのデバッグでははまったく問題ないのに、メインルーチン(main()とか)でエラーになってしまう、思い通りの動きをしない、というケースがあります。それは関数同士の兼ね合い(異なる関数で同じグローバル変数を使ってるとか)で発生するケースもあるし、OSや言語のランタイムのバグで、ある命令の後にある命令を使うと不具合が出る、なんてケースもあります。
こういう場合は、まずどこからが思い通りに動いてないかを発見します。
例えば、あるプログラムで最後に変数$hensuuに1が入ってるはずだし、どんだけソースを見直しても$hensuuに1しか入れてないのに、なぜか$hensuuが最後には""(空文字)になってるという場合、どこから$hensuuの値が破壊されてるか発見しなければなりません。
VisualBasicのようにデバッカーがあれば良いのですが、デバッカーがない時は、とりあえずプログラムのちょうど真ん中で、その変数を表示させてexit()してしまいます。そこまでで$hensuuが破壊されていれば、さらに最初からそこの中間の地点(全体の1/4の所)で変数を表示させてexit()します。逆に、真ん中の地点で異常がなければ、今度は3/4の地点で変数を表示させてexit()させます。
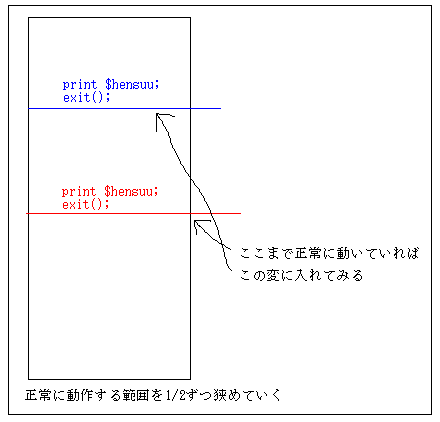
という風に、どんどん中間、中間と範囲をしぼっていけば、最後には変数が破壊されている箇所をつきとめる事ができます。それがメインルーチン内でなかったとしても、ある関数内でたまたま$hensuuというグローバル変数が使われているという場合は、その使ってる関数を特定する事ができます。
こういう場合は、まずどこからが思い通りに動いてないかを発見します。
例えば、あるプログラムで最後に変数$hensuuに1が入ってるはずだし、どんだけソースを見直しても$hensuuに1しか入れてないのに、なぜか$hensuuが最後には""(空文字)になってるという場合、どこから$hensuuの値が破壊されてるか発見しなければなりません。
VisualBasicのようにデバッカーがあれば良いのですが、デバッカーがない時は、とりあえずプログラムのちょうど真ん中で、その変数を表示させてexit()してしまいます。そこまでで$hensuuが破壊されていれば、さらに最初からそこの中間の地点(全体の1/4の所)で変数を表示させてexit()します。逆に、真ん中の地点で異常がなければ、今度は3/4の地点で変数を表示させてexit()させます。
という風に、どんどん中間、中間と範囲をしぼっていけば、最後には変数が破壊されている箇所をつきとめる事ができます。それがメインルーチン内でなかったとしても、ある関数内でたまたま$hensuuというグローバル変数が使われているという場合は、その使ってる関数を特定する事ができます。
アルゴリズムのバグ
いくらバグを探しても、最後まで不具合は治らないケースがあります。それが、アルゴリズムのバグです。下はある人が作った得意先別売上げ明細一覧のプログラムのアルゴリズムです。
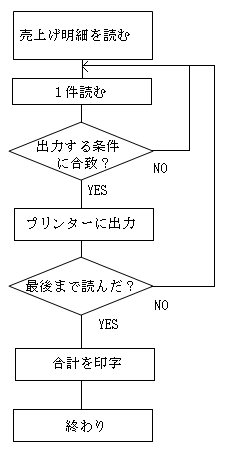
最初はこれでも良かったんですが、日に日に印刷が遅くなってしまいました。それは、全データーを読んで出力条件に合致しないものを読み飛ばす仕様になっているため、データーが増えれば増えるほど遅くなってしまうからです。月に1000件売上げがあったとして1年で12000件、何年も使っていれば遅くて使い物にはならなくなるでしょう。
こういうプログラムでも、ランニングでは不具合は発見できません。なぜなら、ランニングではせいぜい10~20件ぐらい・・多くて100件ぐらいしかデーターは入力しないからです。そんな何万もテストデーターをいれている余裕はプログラマにはありませんし。
また、ペーパーでも中間法でも間違いは発見できません。なぜなら、考え方が間違っている以上、いくらソースを眺めたっておかしいとは思わないでしょう。
今でこそリレーショナルデーターベースという便利なものがありますから、whereで条件を絞って出す事は容易ですが、昔はCOBOLのISAMファイルしかなかったので、該当する条件だけを抽出するために色々工夫が必要でした。明細行1つ1つに得意先コードを入れて副キーにするとか、まずヘッダーファイルを読んでそれに該当する明細ファイルをループで読むとか。いずれにしろ、全データーをチェックしないと一覧1つ出せないようなアルゴリズムにすべきではありません。
アルゴリズムのバグに対しては、修正方法はただ1つ。それは「作り直す」事です。アルゴリズムを多少の変更で修正しようとするとかえってバグを生む結果になりますので、こういう時には素直に作り直します。
最初はこれでも良かったんですが、日に日に印刷が遅くなってしまいました。それは、全データーを読んで出力条件に合致しないものを読み飛ばす仕様になっているため、データーが増えれば増えるほど遅くなってしまうからです。月に1000件売上げがあったとして1年で12000件、何年も使っていれば遅くて使い物にはならなくなるでしょう。
こういうプログラムでも、ランニングでは不具合は発見できません。なぜなら、ランニングではせいぜい10~20件ぐらい・・多くて100件ぐらいしかデーターは入力しないからです。そんな何万もテストデーターをいれている余裕はプログラマにはありませんし。
また、ペーパーでも中間法でも間違いは発見できません。なぜなら、考え方が間違っている以上、いくらソースを眺めたっておかしいとは思わないでしょう。
今でこそリレーショナルデーターベースという便利なものがありますから、whereで条件を絞って出す事は容易ですが、昔はCOBOLのISAMファイルしかなかったので、該当する条件だけを抽出するために色々工夫が必要でした。明細行1つ1つに得意先コードを入れて副キーにするとか、まずヘッダーファイルを読んでそれに該当する明細ファイルをループで読むとか。いずれにしろ、全データーをチェックしないと一覧1つ出せないようなアルゴリズムにすべきではありません。
アルゴリズムのバグに対しては、修正方法はただ1つ。それは「作り直す」事です。アルゴリズムを多少の変更で修正しようとするとかえってバグを生む結果になりますので、こういう時には素直に作り直します。
ヒューマンエラー
エラーを発するのはコンピューターだけではありません。プログラマーの脳みそも頻繁にエラーを発します。それが「ヒューマンエラー」です。
$sql="select hincode, hinmei, suuryo, tanka kingaku from meisai where denban='2';";
$result=pg_qurey($sql);
$Object = pg_fetch_object($result,0);
$hincode = htmlspecialchars($Object->hincode);
$hinmei = htmlspecialchars($Object->hinmei);
$suuryo = htmlspecialchars($Object->suuryo);
$tanka = htmlspecialchars($Object->tanka);
$kingaku = htmlspecialchars($Object->kingaku);
これはデーターベースから商品コード、商品名、数量、単価、金額を読み込んで、同名の変数に代入するプログラムです。(ただし、説明用なのでエラー処理は省いてあります)データーベースから読むと同時にhtmlspecialcharsで<や>の記号を<や>に変換しています。そして画面の伝票イメージに表示します。
フィールド名と同名の変数名を使う事でプログラムの可読性が良くなります。しかし、これが仕様変更でもしも
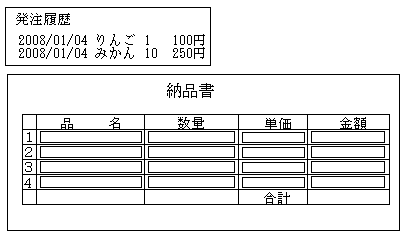
のように、過去の履歴を見ながら入力ができるようになったとします。
過去の履歴を見ながら発注ができるなんて、なんて便利な機能でしょう・・と思いますが、履歴を出す際にもフィールド名と同名の変数が使われる事に注意してください。このままでは1行目に履歴の最後の行(みかん10個)が入力された事になってしまいます。
フィールド名と同じ変数名を使う事は、プログラムの可読性を上げる上で非常に良い事ですが、テーブルから読み込んで、サニタイジングして表示するために一時的に使うためだけに使う変数と、入力させてdbにinsertするために、ブラウザPOSTさせる変数とでは、あきらかに区別する必要があります。でないと、一時的に使っていた$hincodeという変数を見て、これがユーザーが入力した商品コードが入っている変数かと錯覚しかねません。
というように、人間(プログラマ)が錯覚を起こす事を ヒューマンアンデッド ヒューマンエラーと呼びます。
プログラマーはバグを出さない事はもちろんですが、そもそもバグりにくい作りにする必要があります。どちらかというと、そっちの方が大切です。ソースはできる限りわかりやすく、錯覚を起こさないような作りにするという事です。
この例でいくと、一時的に表示用に使う場合、頭にh_という接頭語をつける、データーベースから読み込んだものにはd_をつける、など、そのプロジェクトで統一したルールを作っておけば変数の用途を混乱する事がなくなり、ヒューマンエラーもグンと減ります。
フィールド名と同名の変数名を使う事でプログラムの可読性が良くなります。しかし、これが仕様変更でもしも
のように、過去の履歴を見ながら入力ができるようになったとします。
過去の履歴を見ながら発注ができるなんて、なんて便利な機能でしょう・・と思いますが、履歴を出す際にもフィールド名と同名の変数が使われる事に注意してください。このままでは1行目に履歴の最後の行(みかん10個)が入力された事になってしまいます。
フィールド名と同じ変数名を使う事は、プログラムの可読性を上げる上で非常に良い事ですが、テーブルから読み込んで、サニタイジングして表示するために一時的に使うためだけに使う変数と、入力させてdbにinsertするために、ブラウザPOSTさせる変数とでは、あきらかに区別する必要があります。でないと、一時的に使っていた$hincodeという変数を見て、これがユーザーが入力した商品コードが入っている変数かと錯覚しかねません。
というように、人間(プログラマ)が錯覚を起こす事を ヒューマンアンデッド ヒューマンエラーと呼びます。
プログラマーはバグを出さない事はもちろんですが、そもそもバグりにくい作りにする必要があります。どちらかというと、そっちの方が大切です。ソースはできる限りわかりやすく、錯覚を起こさないような作りにするという事です。
この例でいくと、一時的に表示用に使う場合、頭にh_という接頭語をつける、データーベースから読み込んだものにはd_をつける、など、そのプロジェクトで統一したルールを作っておけば変数の用途を混乱する事がなくなり、ヒューマンエラーもグンと減ります。
変数名ルールの例
| 接頭語 | 用途 | 意味 |
|---|---|---|
| d_ | - | データーベースから読み込んだ直後 |
| h_ | 表示用 | サニタイジング済みの文字列 |
| s_ | SQL用 | ’を’’にするなどして、データーベースにinsert、updateできる状態にしたもの。 |
| p_ | POST | 次の画面にPOSTする用(inputタグ内のname=に指定するなど) |
| g_ | GET | get引数につける用 |
誤解バグ
プログラマーにとってもっとも恐ろしいものが「誤解」という名のバグです。なにしろ、不具合だ、直せ、と言われたって直せないんですよ。バグじゃないわけですから。しかし、エンドユーザーは依然としてあなたに修正を迫ってくるし、修正しなければ納得してもらえないでしょう。
「エラー処理をしよう」のところで述べた通り、麻雀ゲームの店野真澄太というキャラが、負けているのにニコニコしている絵が表示されるのはバグではなく、そういうキャラなのですが、「間違っている」「バグだ」という声が多かったのか、PC-9801版以降では負けると泣いてる顔になってしまいました。
誤解は厳密に言えばバグではありません。しかし、エンドユーザーに「バグだ」「修正しろ」と言われてしまった時は修正しなければなりませんので、バグの発生時と同様のコストを必要とします。つまり、いかなる作業にも優先して修正しなければならず、当然料金も請求できないという事です。なので業務上では誤解もバグと同様に処理しなければなりません。ですので、便宜上ここではそれを誤解バグと定義する事にします。
今でこそ消費税は内税のみになりましたが、外税商品と内税商品が混在している時は、誤解バグの発生する可能性が極めて高い状態にありました。
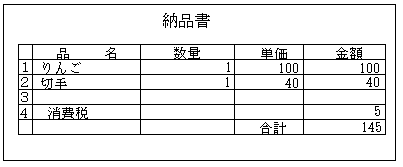
という場合、パッと見て何か変な気がします。消費税は145円の5%だから7円じゃないのか?という気がします。賢明な読者の方ならもうお気づきとは思いますが、切手は内税なのでりんごにだけ消費税が後付けされたわけす。(もっとも現在は全て内税表示ですが)
こういう場合、ある日FAXやメールが送られてきて、「計算が間違ってる」「大至急修正してください」とか言われます。「ハァ?何いってんだコイツ」とか思って無視してると、そのうち大至急修正しろと怒りの電話がかかってきたり、先方の社長からこちらの社長宛てに電話がかかってきたりします。重役同士の話になっても、現場のわかる重役同士なら良いのですが、不幸にも筆者が最初に就職した会社はそういう会社ではありませんで・・・、とにかくそういうケースでは会社対会社の、損害賠償という話を交えた一大トラブルに発展します。
とにかく、現場ではたとえバグでなくとも、バグっぽく見える帳票、バグっぽい挙動は全てバグとして扱われます。これを防ぐためにはもう、バグに見えなくするしかありません。
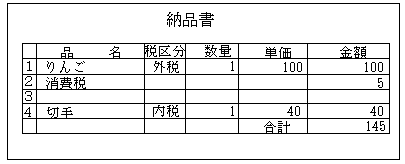
これがその帳票を改良したもので、とにかく外税と内税は分けて表示する、外税と内税の区別を明記するといった事に重点を置いて作られています。これなら、外税商品だけに消費税を後付けしたのが一目でわかるでしょう。
といったように、バグっぽい挙動をするものはできるかぎりバグっぽくない挙動をするようにしなければなりません。誤解バグは通常バグ(?)よりも数段修正に手間がかかるケースがほとんどですから、設計段階でいかに誤解されない作りにするかをよく考えます。
「エラー処理をしよう」のところで述べた通り、麻雀ゲームの店野真澄太というキャラが、負けているのにニコニコしている絵が表示されるのはバグではなく、そういうキャラなのですが、「間違っている」「バグだ」という声が多かったのか、PC-9801版以降では負けると泣いてる顔になってしまいました。

|
⇒ |

|
誤解は厳密に言えばバグではありません。しかし、エンドユーザーに「バグだ」「修正しろ」と言われてしまった時は修正しなければなりませんので、バグの発生時と同様のコストを必要とします。つまり、いかなる作業にも優先して修正しなければならず、当然料金も請求できないという事です。なので業務上では誤解もバグと同様に処理しなければなりません。ですので、便宜上ここではそれを誤解バグと定義する事にします。
今でこそ消費税は内税のみになりましたが、外税商品と内税商品が混在している時は、誤解バグの発生する可能性が極めて高い状態にありました。
という場合、パッと見て何か変な気がします。消費税は145円の5%だから7円じゃないのか?という気がします。賢明な読者の方ならもうお気づきとは思いますが、切手は内税なのでりんごにだけ消費税が後付けされたわけす。(もっとも現在は全て内税表示ですが)
こういう場合、ある日FAXやメールが送られてきて、「計算が間違ってる」「大至急修正してください」とか言われます。「ハァ?何いってんだコイツ」とか思って無視してると、そのうち大至急修正しろと怒りの電話がかかってきたり、先方の社長からこちらの社長宛てに電話がかかってきたりします。重役同士の話になっても、現場のわかる重役同士なら良いのですが、不幸にも筆者が最初に就職した会社はそういう会社ではありませんで・・・、とにかくそういうケースでは会社対会社の、損害賠償という話を交えた一大トラブルに発展します。
とにかく、現場ではたとえバグでなくとも、バグっぽく見える帳票、バグっぽい挙動は全てバグとして扱われます。これを防ぐためにはもう、バグに見えなくするしかありません。
これがその帳票を改良したもので、とにかく外税と内税は分けて表示する、外税と内税の区別を明記するといった事に重点を置いて作られています。これなら、外税商品だけに消費税を後付けしたのが一目でわかるでしょう。
といったように、バグっぽい挙動をするものはできるかぎりバグっぽくない挙動をするようにしなければなりません。誤解バグは通常バグ(?)よりも数段修正に手間がかかるケースがほとんどですから、設計段階でいかに誤解されない作りにするかをよく考えます。
一度確認した所は二度は見ない
昔、ある忍者が城に忍び込みました。しかし、城の警備の侍に見つかって追い詰められました。絶体絶命だったその忍者にあるアイデアが浮かびました。彼は倉庫の巻物の入った箱の中に隠れた後、自分の入ってる箱にはわざとふたを開けっ放しにしておいたのです。
すると侍が来て、ふたのしまった箱を全部チェックし、忍者が隠れていなかったため、倉庫を探すのをあきらめました。しかし、その後も城中を探しても忍者が見つからなかったために、もう一度倉庫を調べることにしました。この時は、さっき調べなかったふたのしてない箱を調べました。しかし、忍者はいませんでした。
忍者はとっさに自分の入ってる箱だけふたを開けっ放しにしておいて、よくよく見れば見つかってしまう状態にしておいたのです。侍はふたのしてある箱に入ってるものだという先入観があったために、ふたのしてない箱をよく見なかったのです。また、さっき調べた箱には入ってないだろうという先入観があったために、2回目には忍者が隠れている場所を替わった事にも気づきませんでした。
というように(って、前置きが長い??)一度調べた所はもう二度と調べない事は、思わぬバグに発展したりします。
すると侍が来て、ふたのしまった箱を全部チェックし、忍者が隠れていなかったため、倉庫を探すのをあきらめました。しかし、その後も城中を探しても忍者が見つからなかったために、もう一度倉庫を調べることにしました。この時は、さっき調べなかったふたのしてない箱を調べました。しかし、忍者はいませんでした。
忍者はとっさに自分の入ってる箱だけふたを開けっ放しにしておいて、よくよく見れば見つかってしまう状態にしておいたのです。侍はふたのしてある箱に入ってるものだという先入観があったために、ふたのしてない箱をよく見なかったのです。また、さっき調べた箱には入ってないだろうという先入観があったために、2回目には忍者が隠れている場所を替わった事にも気づきませんでした。
というように(って、前置きが長い??)一度調べた所はもう二度と調べない事は、思わぬバグに発展したりします。
$hincode=addslashes($hincode);
$hinmei=addslashes($hinmei);
$sql="insert into shohin_m (hincode, hinmei, suu, tanka) values ('$hincode',
'$hinmei', $suu, $tanka)";
$result=pg_qurey($sql);
というデーターベースに商品登録するルーチンがあったとして、これを作った時点では何ら問題なく動作していた、とします。
ところが、実務では最もやっかいな事があります。それが仕様変更です。プログラムというものは、エンドユーザーが実際に業務で使ってみて、実データーを入れてみて、はじめて必要な機能が抜けていた(打ち合わせの時にも気づかなかった)、という事が発覚します。また、実際に使ってみて初めて使い勝手に問題がある事がわかるケースもあります。
あまりに仕様変更が激しい場合、場合によってはケンカ別れというケースもありますが、大抵はそういった事情(つまり、プログラムというものは実際に使ってみないとわからない事が多いという事実)も考慮して、最初のうちは無償で修正をします。しかし、ここに1つ落とし穴があります。それは、最初はまっとうに動いていたプログラムも、仕様変更によって変更した箇所以外の所に影響が出てエラーになってしまう場合があるという事です。
例えば、商品マスターに実は「入り数」が必要だった事が、本稼動してから発覚というわけで、あとから「入り数」を足しました。納品書入力でも入り数が入力できるし、売上げ一覧にも請求明細書にもちゃんと入り数が表示されます。これで、めでたしめでたし・・・ですが、ちょっと待ってください。
商品マスターのところで入り数が登録できるようになってません。先のinsert文にも入り数のフィールドがありません。テーブルに後からalter tableで入り数を足したとしても、insertしてないので、ここにはデフォルト値(がなければnull)が入ってしまいます。
後から仕様が変更された場合に、影響の出そうな所は一通りチェックするものなのですが、どうしても1箇所や2箇所は修正漏れが発生してしまいます。なにより、前に一度デバッグをして何も問題が発生しなかった部分は、再びデバッグされないケースが多いです。もう、そこには不具合はないという記憶が強く残ってしまうからです。
これを防ぐためには、色々方法があります。
・どのプログラムが何のテーブルをいじってるか一覧でまとめる
大抵は仕様書に、プログラム別テーブル一覧というのを作ります。これを見れば、もしテーブルにフィールドの追加があった場合にも、どこを直せば済むか明らかになるでしょう。
ただし、この方法にも欠点がいくつかあります。プロジェクトの最初のうちは仕様変更に伴って仕様書もマメに変更していくのですが、本稼動開始後に緊急で発生した不具合については仕様書の変更が二の次になってしまうケースが多いという事です。なので、仕様書と実際が食い違っている事の方が多く、仕様書を信じたがために、かえって不具合を生み出してしまう事も珍しくありません。なにしろソースこそが唯一の真の仕様書だからです。
・grepを使う
linuxならgrepというコマンドで特定の文字列を発見する事ができます。これで全部のソースを検索して、特定のテーブルを操作している箇所を全部抜き出すことができます。Linuxでなくとも、Windowsで特定のディレクトリ(フォルダ)から特定の文字を含むファイルを抽出するソフトは持っていたほうが良いでしょう。あ、ちなみにWindows標準の犬が穴ほじったりするアニメーション付きの検索機能は、重いしヒットしないケースが多いので、それとは別に用意した方が良いと思います。
・更新履歴を残す
大幅な仕様変更によりソースを変更した場合は、更新履歴をソースのどこかに書いておくと、いつどんな仕様変更があったのかを思い出しやすくなります。また、更新履歴を書く/あとから読む毎に、「どこか他の箇所に影響が出ないだろうか?」と考えることで、仕様変更の影響の直し忘れの防止につながります。
また、あまり考えたくない事ですが、仕様変更しすぎてもうグッチャグチャで、ほとんど1から作り直すという際にも、新履歴があれば前に言われた苦情をまた言われる可能性が減ます。
ところが、実務では最もやっかいな事があります。それが仕様変更です。プログラムというものは、エンドユーザーが実際に業務で使ってみて、実データーを入れてみて、はじめて必要な機能が抜けていた(打ち合わせの時にも気づかなかった)、という事が発覚します。また、実際に使ってみて初めて使い勝手に問題がある事がわかるケースもあります。
あまりに仕様変更が激しい場合、場合によってはケンカ別れというケースもありますが、大抵はそういった事情(つまり、プログラムというものは実際に使ってみないとわからない事が多いという事実)も考慮して、最初のうちは無償で修正をします。しかし、ここに1つ落とし穴があります。それは、最初はまっとうに動いていたプログラムも、仕様変更によって変更した箇所以外の所に影響が出てエラーになってしまう場合があるという事です。
例えば、商品マスターに実は「入り数」が必要だった事が、本稼動してから発覚というわけで、あとから「入り数」を足しました。納品書入力でも入り数が入力できるし、売上げ一覧にも請求明細書にもちゃんと入り数が表示されます。これで、めでたしめでたし・・・ですが、ちょっと待ってください。
商品マスターのところで入り数が登録できるようになってません。先のinsert文にも入り数のフィールドがありません。テーブルに後からalter tableで入り数を足したとしても、insertしてないので、ここにはデフォルト値(がなければnull)が入ってしまいます。
後から仕様が変更された場合に、影響の出そうな所は一通りチェックするものなのですが、どうしても1箇所や2箇所は修正漏れが発生してしまいます。なにより、前に一度デバッグをして何も問題が発生しなかった部分は、再びデバッグされないケースが多いです。もう、そこには不具合はないという記憶が強く残ってしまうからです。
これを防ぐためには、色々方法があります。
・どのプログラムが何のテーブルをいじってるか一覧でまとめる
大抵は仕様書に、プログラム別テーブル一覧というのを作ります。これを見れば、もしテーブルにフィールドの追加があった場合にも、どこを直せば済むか明らかになるでしょう。
ただし、この方法にも欠点がいくつかあります。プロジェクトの最初のうちは仕様変更に伴って仕様書もマメに変更していくのですが、本稼動開始後に緊急で発生した不具合については仕様書の変更が二の次になってしまうケースが多いという事です。なので、仕様書と実際が食い違っている事の方が多く、仕様書を信じたがために、かえって不具合を生み出してしまう事も珍しくありません。なにしろソースこそが唯一の真の仕様書だからです。
・grepを使う
linuxならgrepというコマンドで特定の文字列を発見する事ができます。これで全部のソースを検索して、特定のテーブルを操作している箇所を全部抜き出すことができます。Linuxでなくとも、Windowsで特定のディレクトリ(フォルダ)から特定の文字を含むファイルを抽出するソフトは持っていたほうが良いでしょう。あ、ちなみにWindows標準の犬が穴ほじったりするアニメーション付きの検索機能は、重いしヒットしないケースが多いので、それとは別に用意した方が良いと思います。
・更新履歴を残す
大幅な仕様変更によりソースを変更した場合は、更新履歴をソースのどこかに書いておくと、いつどんな仕様変更があったのかを思い出しやすくなります。また、更新履歴を書く/あとから読む毎に、「どこか他の箇所に影響が出ないだろうか?」と考えることで、仕様変更の影響の直し忘れの防止につながります。
また、あまり考えたくない事ですが、仕様変更しすぎてもうグッチャグチャで、ほとんど1から作り直すという際にも、新履歴があれば前に言われた苦情をまた言われる可能性が減ます。
最後に
作る側と使う側でバグに対する認識は大きく異なります。作る側が意図したとおりに動いていたとしても、使う側は気に入らなければバグと呼び、無償での修正を求めてきます。また、誤解バグなど事前に避けることのできないものも発生します。
そういった状況に対して、いかに早くリカバリーをするか、という事はプログラミングの能力とは別に実務では必要になってきます。そのためには、バグを発見しやすく、発見したらすぐに修正できる状況を常日ごろから準備しておく必要があります。
そういった状況に対して、いかに早くリカバリーをするか、という事はプログラミングの能力とは別に実務では必要になってきます。そのためには、バグを発見しやすく、発見したらすぐに修正できる状況を常日ごろから準備しておく必要があります。
 このページの先頭へ
このページの先頭へ
広告