C言語応用
応用編
C言語は特にLinux上でのプログラミングに威力を発揮します。Linuxではさまざまなライブラリが無償で提供されています。標準でCD-ROMに入っているものの他にもネットを検索すれば、欲しいと思ったライブラリはほぼ手に入る事でしょう。応用編ではLinux上でライブラリを使ってみましょう。
ライブラリをコンパイル&リンクする
既存のライブラリを自作プログラムにリンクする際に、-l オプションと -L オプションを指定します。-lオプションはどのライブラリを組み込むかを指定します。
| -lオプション ライブラリ、lib???.a をリンクする。-lの後に???に該当する部分を指定する。 例) -lz・・・libz.aを組み込む -lpdf・・・libpdf.aを組み込む -lgd・・・libgd.aを組み込む -lpq・・・libpq.aを組み込む |
-Lオプションは、どこからライブラリを探すかを指定します。
| -Lオプション -lオプションで組み込むライブラリの場所を指定する。 例) -L/usr/local/pgsql/lib |
libpqライブラリ
libpqライブラリは、LinuxでCからPostgreSQLを扱うためのAPIを提供するライブラリです。これを使えば、CからPostgreSQLへのアクセスが可能になります。libpqライブラリは、PostgreSQLソース一式(つまり、postgresql-xx.xx.xx.tar.gz)に標準で提供され、PostgreSQLをインストールした際に、/usr/local/pgsql/lib
ディレクトリ(インストール先がデフォルトのままだった場合)にインストールされます。
libpqライブラリではさまざまな変数型を定義する必要があります。これは、libpq-feヘッダで定義されています。プログラムの最初のプリプロセッサを指定しているところに、
libpqライブラリではさまざまな変数型を定義する必要があります。これは、libpq-feヘッダで定義されています。プログラムの最初のプリプロセッサを指定しているところに、
| #include "libpq-fe.h" |
を加えることで、libpqライブラリで使う変数型が使用可能になります。
Makefile
これから作成するプログラム名をdbtest.cとしてMakefileを作ってみましょう。
all : dbtest
dbtest : dbtest.o
cc -g dbtest.o -o dbtest -lpq -L/usr/local/pgsql/lib
dbtest.o : dbtest.c
cc -c dbtest.c -o dbtest.o -I/usr/local/pgsql/include
clean :
-rm dbtest.o dbtest
※この例では説明用に全角スペースを空けていますが、実際にはタブです。このままコピペしても全角スペースでエラーになるので注意しましょう。
このファイル名をMakefileとしておくと、コマンドラインからmakeと入れた時に、自動的にこのファイルが参照され、allで指定されたファイル(つまり、ここではdbtest)が作成されます。ここでは、dbtest、dbtest.o、dbtest.cの依存関係が記述されていて、makeで依存関係とファイルの更新日付を参照して、適切なコンパイルを実行してくれます。
また、make cleanとするとオブジェクトと実行ファイルが消去されます。何らかの理由でコンパイルをやりなおしたい場合に便利です。
このファイル名をMakefileとしておくと、コマンドラインからmakeと入れた時に、自動的にこのファイルが参照され、allで指定されたファイル(つまり、ここではdbtest)が作成されます。ここでは、dbtest、dbtest.o、dbtest.cの依存関係が記述されていて、makeで依存関係とファイルの更新日付を参照して、適切なコンパイルを実行してくれます。
また、make cleanとするとオブジェクトと実行ファイルが消去されます。何らかの理由でコンパイルをやりなおしたい場合に便利です。
ローカルルール
プログラムを作る際に、決めておくと便利なのがローカルルールです。これは筆者の経験則ですが、プロジェクト毎、できれば会社毎に共通したルールを決めておくことで、他の人が作ったプログラムの可読性が高まり、プロジェクトがスムーズに進みます。
もちろん、1人で全て作り上げようというのであれば、自分的なルールでもかまいません。
ローカルルールを定めたら、プリントアウトしてバインダーなどに綴じておくと便利です。テキストファイルでとっておいても良いのですが、その都度ファイルを開かねばならなかったり、使用端末が変わったりしてわからなくなる事があるからです。
例えば、今回はこのようにローカルルールを決めておきます。
もちろん、1人で全て作り上げようというのであれば、自分的なルールでもかまいません。
ローカルルールを定めたら、プリントアウトしてバインダーなどに綴じておくと便利です。テキストファイルでとっておいても良いのですが、その都度ファイルを開かねばならなかったり、使用端末が変わったりしてわからなくなる事があるからです。
例えば、今回はこのようにローカルルールを決めておきます。
| 変数 | 型 | 意味 |
|---|---|---|
| conn | PGconn * | DBコネクト情報へのハンドル |
| conninfo | char * | 接続に関する情報 |
| result | PGresult * | 結果へのハンドル |
| query | char * | ステートメント |
| rows | int | 結果の行数 |
| cols | int | 結果の列数 |
| numberascii | char * | int型のカラムを一時的に取り出すバッファ |
| number | int | int型のカラムを数値に変換するバッファ |
| cnt | int | ループカウンター |
| datalen | int | 結果のデーター長 |
| value | char * | 結果を取り出すコピー元 |
※PGconn型とPGresult型は、ヘッダ(libpq-fe.h)で定義されています。
接続
・準備
接続に関する情報を示した文字列を作成します。
接続に関する情報を示した文字列を作成します。
| host=ホスト名 port=ポート番号 dbname=データーベース名 user=ユーザー名 password=パスワード |
Perlではセミコロンで区切ったのですが、ここではスペースで区切ります。ホスト名は省略するとlocalhostになります。ポート番号は省略すると5432(PostgreSQLのデフォルト)になります。なので、ローカルホストの5432ポートに接続する時は省略する事ができます。
データーベース名、ユーザー名とパスワードは必須です。PostgreSQLに登録されたユーザー名とパスワードを指定します。
個人的なプログラムではchar conninfo[] = "host=localhost …" のように固定値で定義しておくと楽なのですが、会社のプロジェクトで使う時には設定ファイル(.ini)を読み込んで、内部的にこのような文字列を作るように作った方が、後々仕様変更の時に楽になります。
個人で作るプログラムと仕事で作るプログラムの違いは、仕事では仕様変更がとにかく頻繁に発生するという事です。なので、これからプロを目指す方は、後々仕様変更があった際にも対応できるように作るように習慣づけておきましょう。
接続に関する情報を文字列で作成したら、ポインタをconninfoに入れます。
・データーベースへ接続
データーベース名、ユーザー名とパスワードは必須です。PostgreSQLに登録されたユーザー名とパスワードを指定します。
個人的なプログラムではchar conninfo[] = "host=localhost …" のように固定値で定義しておくと楽なのですが、会社のプロジェクトで使う時には設定ファイル(.ini)を読み込んで、内部的にこのような文字列を作るように作った方が、後々仕様変更の時に楽になります。
個人で作るプログラムと仕事で作るプログラムの違いは、仕事では仕様変更がとにかく頻繁に発生するという事です。なので、これからプロを目指す方は、後々仕様変更があった際にも対応できるように作るように習慣づけておきましょう。
接続に関する情報を文字列で作成したら、ポインタをconninfoに入れます。
・データーベースへ接続
/*データーベースへ接続*/
conn = PQconnectdb(conninfo);
PostgreSQLに接続ます。conninfoは先に作成した接続に関する情報です。
この接続に関する情報を管理するメモリ(ディスクリプタ)が確保され、そこのアドレス(ポインタ)が返ってきます。ポインタを、connに入れます。以降、connをこの接続のハンドルとして使います。
・接続の確認
接続がちゃんと正常にできたか確認する処理が必ず必要です。 もちろん、確認する処理がなくてもデバッグ中はおそらく99%何も問題は起こらないでしょうが、実際に運用を開始したときに設定ファイルが間違っていたり、突然サーバーがダウンしたりして、接続がエラーになる事があるからです。
この接続に関する情報を管理するメモリ(ディスクリプタ)が確保され、そこのアドレス(ポインタ)が返ってきます。ポインタを、connに入れます。以降、connをこの接続のハンドルとして使います。
・接続の確認
接続がちゃんと正常にできたか確認する処理が必ず必要です。 もちろん、確認する処理がなくてもデバッグ中はおそらく99%何も問題は起こらないでしょうが、実際に運用を開始したときに設定ファイルが間違っていたり、突然サーバーがダウンしたりして、接続がエラーになる事があるからです。
/*接続がエラーか*/
if (PQstatus(conn) != CONNECTION_OK) {
fprintf(stderr, "%sにコネクト失敗 \n", PQdb(conn));
fprintf(stderr, "%s \n", PQerrorMessage(conn));
exit(EXIT_FAILURE);
}
PQstatus(conn) 関数は、引数で指定した接続に関する情報を返します。CONNECTION_OK値(libpq-fe.hで0と定義されている)であれば、コネクトに成功したという事です。
ということは、それ以外(!=)であれば、コネクトに失敗したとして、エラー処理をします。この例では、接続しようとしたデーターベース名とエラーの原因を表示し、プログラムを終了させています。
ということは、それ以外(!=)であれば、コネクトに失敗したとして、エラー処理をします。この例では、接続しようとしたデーターベース名とエラーの原因を表示し、プログラムを終了させています。
ステートメントの実行
ステートメント(SQL文)を実行します。これによって、データーベースを読み書きする事ができます。
・select文の場合
・select文の場合
/*ステートメントの実行*/
query="select number,onamae from keijiban order by number desc";
result=PQexec(conn,query);
例えば掲示板テーブルから発言番号の大きい順に、発言番号と名前を読む場合。queryとしてこのような文字列を設定しておきます。
ここでは例として直接固定値を代入していますが、実際にはsprintf文で文字列を生成するようにします。ただしCのsprintfは高レベル言語(PerlやPHP)と違い、生成した文字列がバッファ長を越えてしまうとメモリを破壊してしまうので、insert文やupdate文を生成する際には生成される文字列の長さをあらかじめ計算してmallocでメモリーを確保しておく必要があります。
PQexec関数でステートメントを実行します。第一引数には接続ハンドル(conn)を、第二引数にステートメントを入れます。ステートメントを実行したら、結果をチェックします。ステートメントを実行すると、結果を格納する領域がメモリに確保され、ポインタが返ってきますので、resultに入れます。
ここでは例として直接固定値を代入していますが、実際にはsprintf文で文字列を生成するようにします。ただしCのsprintfは高レベル言語(PerlやPHP)と違い、生成した文字列がバッファ長を越えてしまうとメモリを破壊してしまうので、insert文やupdate文を生成する際には生成される文字列の長さをあらかじめ計算してmallocでメモリーを確保しておく必要があります。
PQexec関数でステートメントを実行します。第一引数には接続ハンドル(conn)を、第二引数にステートメントを入れます。ステートメントを実行したら、結果をチェックします。ステートメントを実行すると、結果を格納する領域がメモリに確保され、ポインタが返ってきますので、resultに入れます。
/*ステートメントが失敗したか?*/
if (PQresultStatus(result) != PGRES_TUPLES_OK) {
fprintf(stderr,"ステートメントの実行に失敗しました。%s \n",
PQerrorMessage(conn));
PQclear(result);
PQfinish(conn);
exit(EXIT_FAILURE);
}
PQresultStatus(result)は、直前のコマンドの実行結果を検査する関数です。PGRES_TUPLES_OKは、問合せステートメント(つまり、SELECT文)が成功した、という意味です。ここでは、ステートメントの実行に失敗した場合、エラーメッセージを表示します。PQerrorMessage関数は直前に発生したエラーメッセージを返します。
ステートメントが成功したら、データーを取り出さないといけません。以下、ステートメントを実行した時のハンドル、resultを引数として使います。
ステートメントが成功したら、データーを取り出さないといけません。以下、ステートメントを実行した時のハンドル、resultを引数として使います。
/*結果の行数、列数の表示*/
rows=PQntuples(result);
cols=PQnfields(result);
printf("%d行%d列取得しました。\n",rows,cols);
PQntuplesは、取得した行数を返します。PQnfieldsは取得したカラム数を返します。カラム数はさほど必要ないかもしれませんが、行数は重要で、ループ命令等でデーターを読み出す際に、ループする回数として使います。(
for (cnt=0;cnt<rows;cnt++) のようにします。)
/*データー長の取得*/
datalen=PQgetlength(result, row, col);
PQgetlengthは、取得したデーターのバイト数を返します。rowには行番号、colには列番号を入れます。1行目、1列目は(0,0)です。
PerlやPHPのような高レベル言語と違い、Cではメモリ管理をある程度プログラマの責任で行わねばならないため、返ってくる結果のバイト数は重要になります。ここで問題になってくるのが、PostgreSQLのtextは可変長だという事です。また、バージョン7.xx以降では1行が8192バイトという制約もなく、結果が何バイトかわかりません。なので、以下のように対応します。
(1)バッファを固定長にする
この場合、たとえば掲示板のデーターだった場合、名前やEメール欄、発言の最大長を設定しておきます。そして、最大長を超えた結果が返ってきた場合は、強制的に最大長で切ります。
掲示板などでは、「この掲示板は最大○文字まで発言できます」としておけば、それ以上発言して途中で切れても特に問題はないでしょう。そもそも、CGIの方で切れないように発言長をチェックすればいいわけですから。
(2)バッファを可変長にする
つまり、返ってきたデーターの長さを見てmallocしてメモリを確保し、取り出したデーターが表示や計算に使って不要になった際にfreeで開放する方法です。
この場合、取り出すデーターが小さい場合も、大きい場合もあり得る場合、随時メモリを確保した方が余分なメモリを使わずに済みます。たとえば、普段は10バイト前後のデーターしか出てこないが、たまに1Mバイト近くのデーターも出てくるかもしれない場合、取り出せるデーターの上限を常に確保していてはそれだけメモリが無駄になります。
このような場合は、バッファを可変長にしてその都度メモリを確保した方が効率が良くなります。なので、malloc(datalen)などのようにしてメモリを確保すると良いでしょう。ただし、確保したメモリは不要になった所で必ず開放するようにしないと、メモリが無制限に消費されサーバーがダウンします。(サーバーがスワップしまくりで激重になったりします)
PerlやPHPのような高レベル言語と違い、Cではメモリ管理をある程度プログラマの責任で行わねばならないため、返ってくる結果のバイト数は重要になります。ここで問題になってくるのが、PostgreSQLのtextは可変長だという事です。また、バージョン7.xx以降では1行が8192バイトという制約もなく、結果が何バイトかわかりません。なので、以下のように対応します。
(1)バッファを固定長にする
この場合、たとえば掲示板のデーターだった場合、名前やEメール欄、発言の最大長を設定しておきます。そして、最大長を超えた結果が返ってきた場合は、強制的に最大長で切ります。
掲示板などでは、「この掲示板は最大○文字まで発言できます」としておけば、それ以上発言して途中で切れても特に問題はないでしょう。そもそも、CGIの方で切れないように発言長をチェックすればいいわけですから。
(2)バッファを可変長にする
つまり、返ってきたデーターの長さを見てmallocしてメモリを確保し、取り出したデーターが表示や計算に使って不要になった際にfreeで開放する方法です。
この場合、取り出すデーターが小さい場合も、大きい場合もあり得る場合、随時メモリを確保した方が余分なメモリを使わずに済みます。たとえば、普段は10バイト前後のデーターしか出てこないが、たまに1Mバイト近くのデーターも出てくるかもしれない場合、取り出せるデーターの上限を常に確保していてはそれだけメモリが無駄になります。
このような場合は、バッファを可変長にしてその都度メモリを確保した方が効率が良くなります。なので、malloc(datalen)などのようにしてメモリを確保すると良いでしょう。ただし、確保したメモリは不要になった所で必ず開放するようにしないと、メモリが無制限に消費されサーバーがダウンします。(サーバーがスワップしまくりで激重になったりします)
/*発言ナンバーの取得*/
value=PQgetvalue(result,row,col);
bcopy(value,numberascii,datalen);
number=atoi(numberascii);
ここでは、発言番号を取り出しています。numberasciiは事前にmallocで十分なメモリを確保され、bzeroでクリアされているものとします。
PQgetvalueは取得したデーターが入っているポインタを返します。rowは行番号、colは列番号を入れます。結果をvalueに入れます。データー長は、事前にdatalenに入っているものとします。
データーをbcopyでnumberasciiというバッファに格納します。ただし、この場合PostgreSQLではINT型なのですが、出てくる情報は文字列なため、atoiで数値に変換しています。結果は、numberというINT型の変数に格納されます。
PQgetvalueは取得したデーターが入っているポインタを返します。rowは行番号、colは列番号を入れます。結果をvalueに入れます。データー長は、事前にdatalenに入っているものとします。
データーをbcopyでnumberasciiというバッファに格納します。ただし、この場合PostgreSQLではINT型なのですが、出てくる情報は文字列なため、atoiで数値に変換しています。結果は、numberというINT型の変数に格納されます。
/*名前の取得*/
value=PQgetvalue(result,row,col);
bcopy(value,onamae,datalen);
ここでは、発言者の名前を取り出します。たとえば、発言者名が2列目にある場合は、colには1を入れておきます。(列番号は0から始まるため。)
onamaeは事前にmallocでメモリが確保されbzeroでクリアされているものとします。お名前(ハンドル名)の上限を全角10文字という風にきめておけば、datalenがもし20以上なら、if (datalen>20) { datalen=20; }のように、20バイトで切ってしまっても良いでしょう。(もっとも、文字列が全角の1バイト目で切れると文字化けしますので、切れ目が全角の1バイト目かどうかをチェックする関数が別途必要になりますが。)
onamaeは事前にmallocでメモリが確保されbzeroでクリアされているものとします。お名前(ハンドル名)の上限を全角10文字という風にきめておけば、datalenがもし20以上なら、if (datalen>20) { datalen=20; }のように、20バイトで切ってしまっても良いでしょう。(もっとも、文字列が全角の1バイト目で切れると文字化けしますので、切れ目が全角の1バイト目かどうかをチェックする関数が別途必要になりますが。)
・insert 、 update、 delete文の場合
PerやPHPとは違い、pqlibでは問合せ用ステートメント(SELECT)と、書き換え用ステートメント(insert、update、delete)とでは処理が若干違ってきます。
ステートメントをPQexecで実行させるのは同じですが、エラーをチェックする際に、PGRES_TUPLES_OKが問合せステートメントの正常終了を示すのに対し、データーを書き換えるステートメントは、PGRES_COMMAND_OKが正常終了を表すコードになります。
PerやPHPとは違い、pqlibでは問合せ用ステートメント(SELECT)と、書き換え用ステートメント(insert、update、delete)とでは処理が若干違ってきます。
ステートメントをPQexecで実行させるのは同じですが、エラーをチェックする際に、PGRES_TUPLES_OKが問合せステートメントの正常終了を示すのに対し、データーを書き換えるステートメントは、PGRES_COMMAND_OKが正常終了を表すコードになります。
/*ステートメントが失敗したか?*/
if (PQresultStatus(result) != PGRES_COMMAND_OK) {
fprintf(stderr,"ステートメントの実行に失敗しました。%s \n",
PQerrorMessage(conn));
PQclear(result);
PQfinish(conn);
exit(EXIT_FAILURE);
}
また、Perlでは「問合せステートメントで取得した行数」と、「書き換えステートメントで影響を与えた行数」は共にexecuteステートメントのリターンコードとして返ってきましたが、pqライブラリでは、
PQcmdTuples コマンドで文字列として返してきます。
そのため、影響を受けた行数が必要になった場合は、
そのため、影響を受けた行数が必要になった場合は、
/*影響の受けた行数の取得*/
value=PQcmdTuples(result);
rows=atoi(value);
などのようにして、影響の受けた行数を取り出します。
・メモリの開放
・メモリの開放
/*取得バッファクリア*/
PQclear(result);
ステートメントが終了し、エラーチェックし、必要なデーターをバッファにコピーするなどして処理が終了した後は、必ず最後にメモリを開放しましょう。そうしないと、ステートメントを実行するたびにメモリがどんどん確保され、そのうちメモリ不足でサーバーがダウンしてしまいます。この辺は、高レベル言語であるPerlやPHPよりも神経を使っておきます。
接続終了
/*データーベースとの接続の解除*/
PQfinish(conn);
データーベースとの接続を終了し、接続に必要なメモリを開放します。exit(EXIT_SUCCESS)する前に必ず接続をクローズさせましょう。
libzを使う
libzとは
libzは、Zライブラリ(以下ZLIB)と呼ばれるもので、ZIPやPNGファイル生成に使われる無償の可逆圧縮アルゴリズムです。これは可逆圧縮であり、圧縮率も比較的高いのが特徴です。LinuxはフリーのZLIBを無償でインストールする事ができるため、Linux上のさまざまなプログラムで利用されています。
圧縮するアルゴリズムというのは、必ずそれを考え出した人間がいます。そして、その発明者達はしばしば著作権を主張し、使用料を求めてきます。例えば、画像ファイルをGIF化するためには、GIFアルゴリズム考案者に特許料の支払い義務が生じます。そのため、GIFファイルを生成するプログラムにはGIFの特許料が含まれており、フリーで配布されているものは(ほぼ)なくなってしまいました。
逆にpngという圧縮方式には、ZLIBを使った圧縮アルゴリズムが採用されており、こちらは無償で使用する事ができます。そのため、GDライブラリも途中からGIFのサポートを中止し、PNGのサポートに切り替えました。(※ただし、現在ではGIFの特許が切れたため、GIFのサポートが復活しています)
libzは、Zライブラリ(以下ZLIB)と呼ばれるもので、ZIPやPNGファイル生成に使われる無償の可逆圧縮アルゴリズムです。これは可逆圧縮であり、圧縮率も比較的高いのが特徴です。LinuxはフリーのZLIBを無償でインストールする事ができるため、Linux上のさまざまなプログラムで利用されています。
圧縮するアルゴリズムというのは、必ずそれを考え出した人間がいます。そして、その発明者達はしばしば著作権を主張し、使用料を求めてきます。例えば、画像ファイルをGIF化するためには、GIFアルゴリズム考案者に特許料の支払い義務が生じます。そのため、GIFファイルを生成するプログラムにはGIFの特許料が含まれており、フリーで配布されているものは(ほぼ)なくなってしまいました。
逆にpngという圧縮方式には、ZLIBを使った圧縮アルゴリズムが採用されており、こちらは無償で使用する事ができます。そのため、GDライブラリも途中からGIFのサポートを中止し、PNGのサポートに切り替えました。(※ただし、現在ではGIFの特許が切れたため、GIFのサポートが復活しています)
可逆圧縮と不可逆圧縮
可逆圧縮とは
可逆圧縮とは、圧縮したものが完全に元に戻せる圧縮方式のことです。
フリーソフトをサイトにアップする時は、LHAやZIPで圧縮してアップすると思います。そして、ダウンした人がlhasa等を使って解凍して元のプログラムにして使うわけですが、これは完全に元に戻せないと困ります。圧縮されたファイルを解凍したらエラーになったりバグが増えたりしたのでは使い物にならないでしょう。
このように、プログラムを配布する際には絶対に完全に元に戻せる圧縮方式が求められます。ZLIBは完全に元に戻せる可逆圧縮です。
可逆圧縮とは、圧縮したものが完全に元に戻せる圧縮方式のことです。
フリーソフトをサイトにアップする時は、LHAやZIPで圧縮してアップすると思います。そして、ダウンした人がlhasa等を使って解凍して元のプログラムにして使うわけですが、これは完全に元に戻せないと困ります。圧縮されたファイルを解凍したらエラーになったりバグが増えたりしたのでは使い物にならないでしょう。
このように、プログラムを配布する際には絶対に完全に元に戻せる圧縮方式が求められます。ZLIBは完全に元に戻せる可逆圧縮です。
不可逆圧縮とは
不可逆圧縮とは、完全には元に戻せない圧縮方式のことです。
例えば、写真やCGイラストなどを自サイトにアップする時には、なるべく画質を犠牲にしてサイズが小さくなるように指定したJPGファイルでアップしたり、あるいは256色以下に減色してGIF形式でアップしたりするでしょう。
また、音楽CDをiPOD等のポータブルプレイヤーに入れて再生する時には、mp3という方式で圧縮してから入れると思いますが、これは人間の耳ではほぼ判別できないレベルに音を間引いてしまうため、サイズは小さくなりますが、いったん圧縮してしまうとまったく元の音質に戻すことはできなくなります。
しかし、画像や音楽などは人間が見て聴いて満足できればいいわけで、必ずしも完全に同じものを作る必要がないわけです。
不可逆圧縮は、可逆圧縮より圧縮率が高いのが普通です。たとえば、2~3分の曲を1曲wavファイルにすると20~30メガバイト近くになりますが、これを不可逆圧縮であるmp3に圧縮すると3~4メガバイトまで圧縮する事ができます。ところが、可逆圧縮であるape方式で圧縮しても、15~20メガバイトぐらいにしかなりません。
このように、元に戻せない事をあきらめるかわりに、高い圧縮率を実現するものが不可逆圧縮です。
不可逆圧縮とは、完全には元に戻せない圧縮方式のことです。
例えば、写真やCGイラストなどを自サイトにアップする時には、なるべく画質を犠牲にしてサイズが小さくなるように指定したJPGファイルでアップしたり、あるいは256色以下に減色してGIF形式でアップしたりするでしょう。
また、音楽CDをiPOD等のポータブルプレイヤーに入れて再生する時には、mp3という方式で圧縮してから入れると思いますが、これは人間の耳ではほぼ判別できないレベルに音を間引いてしまうため、サイズは小さくなりますが、いったん圧縮してしまうとまったく元の音質に戻すことはできなくなります。
しかし、画像や音楽などは人間が見て聴いて満足できればいいわけで、必ずしも完全に同じものを作る必要がないわけです。
不可逆圧縮は、可逆圧縮より圧縮率が高いのが普通です。たとえば、2~3分の曲を1曲wavファイルにすると20~30メガバイト近くになりますが、これを不可逆圧縮であるmp3に圧縮すると3~4メガバイトまで圧縮する事ができます。ところが、可逆圧縮であるape方式で圧縮しても、15~20メガバイトぐらいにしかなりません。
このように、元に戻せない事をあきらめるかわりに、高い圧縮率を実現するものが不可逆圧縮です。
ZLIBを使う準備
1.インストール
ZLIBを使うためには、まずサーバーにZLIBをインストールしなければなりません。 RedHat系(Fedora, RedHat Enterprise, CentOS 等)ならOSインストール時にデベロッパーツールとして入れておくのも手ですし、後からRPMをインストールしても良いでしょう。 それ以外のディストリビューションでは、ソースをコンパイルしてインストールしてもいいでしょう。
その際にソースコード一式は、 この辺(http://www.zlib.net/)からダウンロードしてください。 インストールすると、
/usr/lib/libz.a
/usr/include/zlib.h
というファイルがインストールされると思います。
2.ヘッダーの追加
zlibを使うために、ヘッダーファイルを追加します。
ZLIBを使うためには、まずサーバーにZLIBをインストールしなければなりません。 RedHat系(Fedora, RedHat Enterprise, CentOS 等)ならOSインストール時にデベロッパーツールとして入れておくのも手ですし、後からRPMをインストールしても良いでしょう。 それ以外のディストリビューションでは、ソースをコンパイルしてインストールしてもいいでしょう。
その際にソースコード一式は、 この辺(http://www.zlib.net/)からダウンロードしてください。 インストールすると、
/usr/lib/libz.a
/usr/include/zlib.h
というファイルがインストールされると思います。
2.ヘッダーの追加
zlibを使うために、ヘッダーファイルを追加します。
#include <zlib.h>
3.コンパイルの指示
コンパイル、リンクする際に、libz.aをリンクするように指示します。たとえば、これから作るプログラムがztestであるなら、Makefileは以下のようになります。
コンパイル、リンクする際に、libz.aをリンクするように指示します。たとえば、これから作るプログラムがztestであるなら、Makefileは以下のようになります。
all : ztest
ztest : ztest.o
cc -g ztest.o -o ztest -lz
ztest.o : ztest.c
cc -c ztest.c -o ztest.o
clean :
-rm ztest.o ztest
ここではコンパイルとリンクを別々に行っています。今回は単一プログラムのコンパイルなので必要ないのですが、複数のプログラムを最後に結合して実行ファイルを作るように応用を利かせるために、コンパイルとリンクは別々に行う方が良いです。
リンクの際に、-lzオプションを指定しています。これは、libz.aを使うという意味です。(ライブラリを指定する時は、頭のlibと後ろの.aを省いたものを指定します。)
リンクの際に、-lzオプションを指定しています。これは、libz.aを使うという意味です。(ライブラリを指定する時は、頭のlibと後ろの.aを省いたものを指定します。)
バッファの考え方
データーを圧縮する時に、困ることが2つあります。
1.入力バッファの泣き別れ
例えば、00 00 00 00 00 ……… という、20バイトの0が、2バイトの1C 2Aというコードに圧縮できるとします。(あくまでも、例えばですよ)。ところが、18バイト目のところで入力バッファオーバーでデーターが切れちゃう事があります。(これを、ここでは「バッファの泣き別れ」と呼ぶことにします)
この場合、ZLIBは、圧縮が確定できた所までを圧縮し、まだ圧縮が確定してない部分は内部で保留にしておきます。

この例では、後ろ3バイト分が内部で保留になっています。
そして、続くバイトとあわせて圧縮バイトを確定させます。
2.出力バッファの泣き別れ
例えば、00 00 00 00 00 ……… という、20バイトの0が、2バイトの1C 2Aというコードに圧縮できるとします。が、1Cのところでバッファがいっぱいになってしまった場合、のこりの2Cは内部で保留になります。
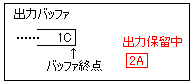
保留になった分は、次回この関数が呼び出された際に出力されます。
1.入力バッファの泣き別れ
例えば、00 00 00 00 00 ……… という、20バイトの0が、2バイトの1C 2Aというコードに圧縮できるとします。(あくまでも、例えばですよ)。ところが、18バイト目のところで入力バッファオーバーでデーターが切れちゃう事があります。(これを、ここでは「バッファの泣き別れ」と呼ぶことにします)
この場合、ZLIBは、圧縮が確定できた所までを圧縮し、まだ圧縮が確定してない部分は内部で保留にしておきます。
この例では、後ろ3バイト分が内部で保留になっています。
そして、続くバイトとあわせて圧縮バイトを確定させます。
2.出力バッファの泣き別れ
例えば、00 00 00 00 00 ……… という、20バイトの0が、2バイトの1C 2Aというコードに圧縮できるとします。が、1Cのところでバッファがいっぱいになってしまった場合、のこりの2Cは内部で保留になります。
保留になった分は、次回この関数が呼び出された際に出力されます。
保留バイトを考慮する
このように、入力バッファにも出力バッファにも、内部的に保留になっているバイトが存在している事を常に意識しなければなりません。
1.入力バッファの保留対策
入力バッファがまだこれから先にも続くのか、これで終わりなのかをライブラリに知らせる必要があります。具体的には第二引数にて指定します。
1.入力バッファの保留対策
入力バッファがまだこれから先にも続くのか、これで終わりなのかをライブラリに知らせる必要があります。具体的には第二引数にて指定します。
| deflate(ポインタ, 継続モード) 第一引数:z_stream型構造体へのポインターを指定します。 第二引数:継続モードを指定します。 ※継続モード Z_NO_FLUSH・・・・・・まだ入力データーが続く Z_FINISH・・・・・・・・・もう入力データーはこれで終り |
たとえば、deflate(zstp,Z_NO_FLUSH)と指定すると、入力データーはこの後に続く事がライブラリに伝わり、後ろ数バイトが圧縮確定をせずに保留になる場合があります。また、deflate(zstp,Z_FINISH)とすると、もうこれ以上先にデーターがない事がライブラリに伝わります。
第二引数にZ_FINISHを入れてライブラリを呼ぶと、入力バッファの最後まで保留にならずに圧縮処理が行われますが、出力バッファがいっぱいになってしまう事もありますので、この後、出力バッファの保留対策をしなければなりません。
2.出力バッファの保留対策
これは、Z_FINISHモードでライブラリを呼び出したときに、リターンコードを見て判断します。
第二引数にZ_FINISHを入れてライブラリを呼ぶと、入力バッファの最後まで保留にならずに圧縮処理が行われますが、出力バッファがいっぱいになってしまう事もありますので、この後、出力バッファの保留対策をしなければなりません。
2.出力バッファの保留対策
これは、Z_FINISHモードでライブラリを呼び出したときに、リターンコードを見て判断します。
| リターンコード Z_OK・・・・・・・・・・・・・ 正常終了。ただし、この後にまだ出力データーがある可能性あり。 Z_STREAM_END ・・・・ 正常終了。もう出力データーはない。 |
Z_NO_FLUSHモードで呼び出した場合は、この後に出力データーが残ってるかもしれないし、残ってないかもしれませんが、リターンコードは必ずZ_OKになります。
Z_FINISHモードで呼び出しても、リターンコードがZ_OKだった場合は出力バッファが足りません。これまでの出力バッファをファイルや別の領域に吐き出して、空にしてから再度呼び出す必要があります。
Z_FINISHモードで呼び出して、リターンコードがZ_STREAM_ENDだった場合は本当に終了です。
Z_FINISHモードで呼び出しても、リターンコードがZ_OKだった場合は出力バッファが足りません。これまでの出力バッファをファイルや別の領域に吐き出して、空にしてから再度呼び出す必要があります。
Z_FINISHモードで呼び出して、リターンコードがZ_STREAM_ENDだった場合は本当に終了です。
圧縮のアルゴリズム
以上のことを考慮して、このようなアルゴリズムを作る事にします。
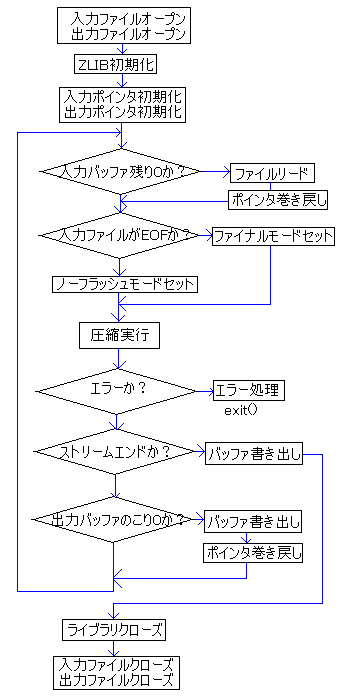
入力ポインタと出力ポインタはあらかじめバッファの先頭アドレスにセットしておきます。また、入力バッファの残りは0、出力バッファの残りは出力バッファサイズそのものにセットしておきます。
入力バッファの残りが0だったら、ファイルから読んでバッファに補充します。この時に入力バッファのポインタをバッファの先頭にリセット(巻き戻し)します。
ファイルの読み込みが完了していたらファイナルモード、完了してなければノーフラッシュモードにセットします。
圧縮を実行します。
リターンコードをチェックし、エラーなら異常終了させます。また、ストリームエンドだったら、出力バッファの残りをファイルに書き出して終了処理へ行きます。
出力バッファの残りが0になったら、ファイルにバッファの内容を書き出して、出力ポインターを巻き戻します。(つまり、出力バッファの先頭アドレスを元に戻して、残りバイト=バッファサイズにします。)
圧縮が完了したら、ライブラリとファイルをクローズします。
入力ポインタと出力ポインタはあらかじめバッファの先頭アドレスにセットしておきます。また、入力バッファの残りは0、出力バッファの残りは出力バッファサイズそのものにセットしておきます。
入力バッファの残りが0だったら、ファイルから読んでバッファに補充します。この時に入力バッファのポインタをバッファの先頭にリセット(巻き戻し)します。
ファイルの読み込みが完了していたらファイナルモード、完了してなければノーフラッシュモードにセットします。
圧縮を実行します。
リターンコードをチェックし、エラーなら異常終了させます。また、ストリームエンドだったら、出力バッファの残りをファイルに書き出して終了処理へ行きます。
出力バッファの残りが0になったら、ファイルにバッファの内容を書き出して、出力ポインターを巻き戻します。(つまり、出力バッファの先頭アドレスを元に戻して、残りバイト=バッファサイズにします。)
圧縮が完了したら、ライブラリとファイルをクローズします。
実際に作ってみる
では実際に作ってみましょう。
・ヘッダー
ヘッダーは上で説明した通り、#include <zlib.h>です。zlibが正しくインストールされていれば、標準ライブラリ/usr/includeまたは/usr/local/include等から探してくれます。(標準ライブラリ以外の場所にヘッダーがある時は、リンク時に-Lで指定します)
・ワークエリアの用意
・ヘッダー
ヘッダーは上で説明した通り、#include <zlib.h>です。zlibが正しくインストールされていれば、標準ライブラリ/usr/includeまたは/usr/local/include等から探してくれます。(標準ライブラリ以外の場所にヘッダーがある時は、リンク時に-Lで指定します)
・ワークエリアの用意
/*圧縮型*/
typedef struct {
z_stream *zstp; /* z_sreamへのポインター */
char *sbuff; /* 圧縮解凍元バッファ */
int sbuffsize; /* 圧縮解凍元バッファのサイズ */
int sbuffryo; /* 圧縮解凍元バッファに入ってる量 */
char *dbuff; /* 圧縮解凍先バッファ */
int dbuffsize; /* 圧縮解凍先バッファのサイズ */
int dbuffryo; /* 圧縮解凍先バッファに入ってる量 */
int errorcode; /* エラーの原因 */
char *zliberrmsg; /* zlibの発したエラーメッセージ */
int readdisc; /* リードファイルディスクリプタ */
int writedisc; /* ライトファイルディスクリプタ */
int eofflg; /* ファイルが終わりフラグ */
} T_COMPRESS;
「ワークエリア」というのは、「ある決まった作業をするためにメモリに確保された領域」のことです。
メモリーはそれぞれ用途に応じて「プログラム」[ワーク」「データー」という風に分類して使います。プログラムエリアには文字通りプログラムが入ります。データーエリアには、例えばCGを表示する場合ディスクから読み込んだCGのデーターが入ります。
ワークエリアとは、つまり、一時的に記録しておくフラグやカウンター類を入れるためのエリアのことです。これを構造体として定義しておくことで、main()内や他の関数内でも共通して同じワークエリアを使う事ができるようになります。
・z_stram型変数の確保
zlibを使うためには、ライブラリのワークエリア(z_stram型変数)を確保する必要があります。これは、実態を宣言して確保してもいいのですが、ここではmain()内でも関数内でも同じように扱うために、ポインターで宣言してmallocで領域を確保することにします。
メモリーはそれぞれ用途に応じて「プログラム」[ワーク」「データー」という風に分類して使います。プログラムエリアには文字通りプログラムが入ります。データーエリアには、例えばCGを表示する場合ディスクから読み込んだCGのデーターが入ります。
ワークエリアとは、つまり、一時的に記録しておくフラグやカウンター類を入れるためのエリアのことです。これを構造体として定義しておくことで、main()内や他の関数内でも共通して同じワークエリアを使う事ができるようになります。
・z_stram型変数の確保
zlibを使うためには、ライブラリのワークエリア(z_stram型変数)を確保する必要があります。これは、実態を宣言して確保してもいいのですが、ここではmain()内でも関数内でも同じように扱うために、ポインターで宣言してmallocで領域を確保することにします。
z_stream *l_zstp; /*z_stream型ポインター宣言*/
/* z_stram型領域確保 */
if (NULL==(l_zstp=(z_stream*)malloc(sizeof(z_stream)))) {
fprintf(stderr,"メモリーが足りません \n");
exit(EXIT_FAILURE);
}
bzero(l_zstp,sizeof(z_stream));
「○○型変数の確保」の場合のおなじみの手段として、mallocの引数にsizeof(変数型)と書き、変数型のサイズが後で変わっても書き換えなくても良いようにします。また、mallocは基本的にchar*型(つまり1バイト単位で繰り上がるポインター)を返すので、代入前に適切な型にキャストします。
同様に、先に定義したT_COMPRESS型の領域も確保しておきいます。
・zlib初期化
同様に、先に定義したT_COMPRESS型の領域も確保しておきいます。
・zlib初期化
/*zlib初期化*/
l_zstp->zalloc = Z_NULL;
l_zstp->zfree = Z_NULL;
l_zstp->opaque = Z_NULL;
if ((deflateInit(l_zstp, Z_DEFAULT_COMPRESSION))!=Z_OK) {
fprintf(stderr,"zlibの初期化に失敗しました。\n");
fprintf(stderr,"[%s]\n",l_zstp->msg);
exit(EXIT_FAILURE);
}
ここでは、メモリ管理の方法と圧縮レベルを指定します。
| deflateInit(z_stream型へのポインター, 圧縮レベル)
リターンコード Z_OK:正常終了 それ以外:エラー |
初期化を呼び出す前に、事前にメモリの確保の関数(zalloc)、開放の関数(zfree)、確保や解放する場合の引数の場所(opaque)を指定します。しかし、普通はそこまで自力で作る必要はなく、全てにZ_NULLを指定しておけばライブラリの方で自動的にやってくれます。大抵はこれを指定します。
圧縮レベルは、0~9まであり、数字が高くなるほど圧縮率は高くなります。(高くなる事が期待できます。)そのかわり、計算に時間がかかります。大抵は、Z_DEFAULT_COMPRESSIONを指定しておけばいいでしょう。(※Z_DEFAULT_COMPRESSIONは、現バージョンではzlib.hで「6」と定義されています。)
エラーが発生した場合、ポインタ->msgにエラーメッセージが入ります。(※エラーメッセージの入ってるアドレスのポインタが入ります)エラーメッセージは\0で区切られているので、そのままprintfする事ができます。
・バッファとポインタの用意
圧縮するためには、圧縮元バッファ、圧縮元ポインター、圧縮先バッファ、圧縮先ポインターが必要です。
next_in ・・・圧縮元バッファ
avail_in・・・・圧縮元ポインター
next_out・・・圧縮先バッファ
avail_out・・・圧縮先ポインター
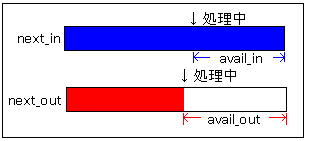
圧縮元バッファにファイルから読んでデーターを入れておきます。そして先頭アドレス(ポインター)をnext_inにセットします。avail_inは上図のように、圧縮元バッファのうちの何バイトが未処理かをセットします。なので、[初期値=ファイルから読み込んだ量]です。
圧縮先バッファはあらかじめmallocで確保して、先頭アドレス(ポインター)をnext_outにセットします。avail_outは上図のように、圧縮先バッファがあと何バイト残っているかです。なので、[初期値=確保したメモリーの量]です。
avail_inの初期値は確保したバッファのサイズと誤解する人がいますが、そうではありません。ファイルやソケットからread()関数でデーターを読み込む場合、必ずしもバッファの上限までデーターが読み込まれるとは限らないためです。avail_inの初期値はあくまでファイルやソケットから読み込んだ時のリターンコードをセットしてください。
avail_inはあくまで初期値をセットするだけです。avail_inは圧縮元バッファに入ってる量ではなく、圧縮元バッファに入ってるデータ-のうちまだ未処理分がいくらあるかを示すものですので、あとはzlibを呼び出すごとに変動します。
avail_outもあくまで初期値として確保したメモリ量をセットするだけです。avail_outは確保したメモリ量を常に示すものではありません。確保したメモリのうちのまだ使える分がどれぐらいあるかを示すものです。zlibを呼び出すたびに残りの量を減らしていきます。
ここでは、avail_inに読み込んだバイト数をセットすることを、「圧縮元ポインターを巻き戻す」と呼びます。また、avail_outに確保したメモリー量をセットすることは「圧縮先ポインターを巻き戻す」と呼びます。
・圧縮実行
圧縮レベルは、0~9まであり、数字が高くなるほど圧縮率は高くなります。(高くなる事が期待できます。)そのかわり、計算に時間がかかります。大抵は、Z_DEFAULT_COMPRESSIONを指定しておけばいいでしょう。(※Z_DEFAULT_COMPRESSIONは、現バージョンではzlib.hで「6」と定義されています。)
エラーが発生した場合、ポインタ->msgにエラーメッセージが入ります。(※エラーメッセージの入ってるアドレスのポインタが入ります)エラーメッセージは\0で区切られているので、そのままprintfする事ができます。
・バッファとポインタの用意
圧縮するためには、圧縮元バッファ、圧縮元ポインター、圧縮先バッファ、圧縮先ポインターが必要です。
next_in ・・・圧縮元バッファ
avail_in・・・・圧縮元ポインター
next_out・・・圧縮先バッファ
avail_out・・・圧縮先ポインター
圧縮元バッファにファイルから読んでデーターを入れておきます。そして先頭アドレス(ポインター)をnext_inにセットします。avail_inは上図のように、圧縮元バッファのうちの何バイトが未処理かをセットします。なので、[初期値=ファイルから読み込んだ量]です。
圧縮先バッファはあらかじめmallocで確保して、先頭アドレス(ポインター)をnext_outにセットします。avail_outは上図のように、圧縮先バッファがあと何バイト残っているかです。なので、[初期値=確保したメモリーの量]です。
avail_inの初期値は確保したバッファのサイズと誤解する人がいますが、そうではありません。ファイルやソケットからread()関数でデーターを読み込む場合、必ずしもバッファの上限までデーターが読み込まれるとは限らないためです。avail_inの初期値はあくまでファイルやソケットから読み込んだ時のリターンコードをセットしてください。
avail_inはあくまで初期値をセットするだけです。avail_inは圧縮元バッファに入ってる量ではなく、圧縮元バッファに入ってるデータ-のうちまだ未処理分がいくらあるかを示すものですので、あとはzlibを呼び出すごとに変動します。
avail_outもあくまで初期値として確保したメモリ量をセットするだけです。avail_outは確保したメモリ量を常に示すものではありません。確保したメモリのうちのまだ使える分がどれぐらいあるかを示すものです。zlibを呼び出すたびに残りの量を減らしていきます。
ここでは、avail_inに読み込んだバイト数をセットすることを、「圧縮元ポインターを巻き戻す」と呼びます。また、avail_outに確保したメモリー量をセットすることは「圧縮先ポインターを巻き戻す」と呼びます。
・圧縮実行
| deflate(z_stream型へのポインター, モード)
リターンコード Z_OK・・・まだ続くかも Z_STREAM_END・・・もうおしまい それ以外・・・エラー |
圧縮を実行する関数です。z_stream型へのポインターとモードを指定します。
モードには、Z_NO_FLUSHとZ_FINISHがありますが、これもめんどいので、ここでは「ノーフラッシュモード」と「フィニッシュモード」と呼ぶことにしましょう。
ノーフラッシュモードは、つまりは「この先まだデーターが続くかも」という意味で、フィニッシュモードは「もうこの先にデーターはないよ」という意味です。
しかし、read()関数を使ってファイルやソケットからデーターを読み込む場合、終わってみないと終わりかどうかわかりませんので、終わったときには、avail_inを0にして、フィニッシュモードで呼ぶことにします。
リターンコードは、Z_OKかZ_STREAM_ENDが返ったら正常終了ですが、Z_OKの場合は「まだこの先データーが続くかも」という意味です。Z_STREAM_ENDではじめて本当に処理が終わったことを示します。
それ以外のリターンコードはエラーですので、エラー処理を行います。(z_stream*)->msgにエラーメッセージの場所が返ってきます。エラーメッセージは\0で区切られていますのでそのままprintf等で表示させることができます。
モードには、Z_NO_FLUSHとZ_FINISHがありますが、これもめんどいので、ここでは「ノーフラッシュモード」と「フィニッシュモード」と呼ぶことにしましょう。
ノーフラッシュモードは、つまりは「この先まだデーターが続くかも」という意味で、フィニッシュモードは「もうこの先にデーターはないよ」という意味です。
しかし、read()関数を使ってファイルやソケットからデーターを読み込む場合、終わってみないと終わりかどうかわかりませんので、終わったときには、avail_inを0にして、フィニッシュモードで呼ぶことにします。
リターンコードは、Z_OKかZ_STREAM_ENDが返ったら正常終了ですが、Z_OKの場合は「まだこの先データーが続くかも」という意味です。Z_STREAM_ENDではじめて本当に処理が終わったことを示します。
それ以外のリターンコードはエラーですので、エラー処理を行います。(z_stream*)->msgにエラーメッセージの場所が返ってきます。エラーメッセージは\0で区切られていますのでそのままprintf等で表示させることができます。
サンプルプログラム
今までのことをふまえて作ったサンプルがありますので、参考にしてください。
→ztest.cをダウンロードする
→ztest.cをダウンロードする
 このページの先頭へ
このページの先頭へ
広告