データーベース入門
データーベースについて
データーベースとは何か?
データーベースとは、住所録や電話帳のような、データーを管理するためのシステムの事です。例えば、携帯電話には名前・電話番号・メールアドレス等を入力して友達や仕事上で使う連絡先を登録して管理する機能があります。これも一種のデーターベースです。
お店などから届くダイレクトメールには、宛先(住所氏名)が印刷されています。これは、送信側のお店が顧客をコンピューターで管理しているからです。つまり、データーベースを使っているわけです。(小規模なお店では、単にワープロで打ってるだけかもしれませんが・・・)。
シーケンシャルファイル
データーを管理する場合、簡単なのが、テキストファイルとしてエディターに直接手入力することです。そうすれば、エディターの検索機能を使って、欲しい情報をすぐに取り出す事ができます。
例1:テキストファイルでデーターを管理する場合
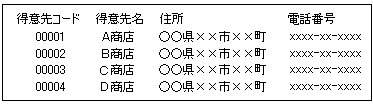
ちょっと進んでCVSファイルになっていれば、エクセルやアクセスなど、市販のアプリに読み込んでダッグシール印刷等に加工することもできるでしょう。
例2:CVSファイルでデーターを管理する場合

このようなファイルをシーケンシャルファイルといい、特にテキストエディターで簡単に入力/閲覧のできるファイルをプレーンテキストファイルと呼びます。
シーケンシャルファイルの長所は、とにかく扱いが楽なことです。楽というのは、つまり、エディターで開いて検索して該当個所を書き換えればいいわけですから、特にデーターベースの知識のない人でも扱えますし、小規模な顧客管理ではこれでも十分すぎるほどです。
しかしながら、これが顧客が1000件、1000万件と増えてきた場合、一箇所訂正/削除するにも必ず全部のデーターをメモリに読み込んで、検索して、書き換えて、全部のデーターをハードディスクにリライトしなければなりません。
これでは、メモリがいくらあっても足りませんし、読み込み→検索→リライトの作業にとてつもなく時間がかかってしまいます。ましてや、得意先を郵便番号順にソートしたい、とか、売上順にソートしたい、なんて場合にも、全部を読み込んでソートしなければならないため非常に時間がかかります。
そのため、データーをシーケンシャルファイルで管理するのは、データー自体が小規模で、将来的にも増える可能性がない場合のみ、という事になります。
・ランダムアクセスファイル
得意先1件あたりのバイト数(たとえば、256バイト)を決めておいて、2件目なら257バイト目、3件目なら513バイト目・・・という風に、該当個所のみを読み書きする方式があります。これを、ランダムアクセスファイルといいます。
例3:ランダムアクセスファイル

これならば、n件目のデーターを読む場合は、an=(n-1)d + 1バイト目を読み込めば良いことになります。(余談ですが、コンピューターでは普通、計算しやすいように先頭バイトを「0バイト目」と考えますので、2件目は256バイト目、3件目は512バイト目という事になります。)この方式ならば、得意先1000件中の999件目を出したいという場合でも、全てのデーターを読み込むことなく、即座に欲しいデーターを取り出すことができます。
しかし、この方式には欠点がたくさんあります。
欠点1:固定長になってしまう
これはかなり致命的で、一度得意先の情報を256バイトと決めてしまうと、後から仕様変更で256バイトで足りなくなった場合に、データーをコンバートしないといけません。逆に256バイトに満たない場合は無駄に0x00等で埋めなくてはなりません。(これをfillerといいます。)
欠点2:○件目という出し方しかできない
つまり、得意先コードが連番なら良いのですが、1番の次が10000番というわけにはいきません。必ず、1から順に欠番なくコードをわりふらなくてはなりません。また、連番以外ではデーターが出せません。もし、「電話番号 xxxx-xx-xxxxの得意先を出せ」といわれても、全部のデーターを調べなくてはいけません。
このように、欠点だらけの方式ですが、なぜこのような方式があるかというと、昔の8ビットパソコン+フロッピーディスクの時代には、この方式しか大量のデーターを管理するすべがなかったのです。つまり、ディスクの読み書きも、パソコンの処理も低速な機械であっても、この方式であれば、ある程度のデーター管理ができたわけです。
・索引編成ファイル
ランダムアクセスファイルから少し進化したものが、この索引編成ファイルです。
例4:索引編成ファイル
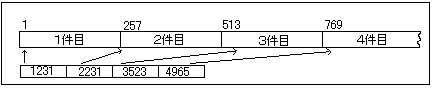
図のように、得意先コード1231は1件目、2231は2件目…という風に、キー(索引)をつくり、まず索引にアクセスしてから該当データーを読み込む方式です。ISAMファイルともいいます。
得意先コードに、1231といった飛び番を使うことができる他、AA001みたいな英文字も扱うことができます。
この方式の欠点は、ランダムアクセスファイルと同様、データーを固定長にしないといけない事です。また、得意先コード以外にも電話番号でも検索できるようにしたい時には電話番号の索引(副キー)も作らねばなりません。
また、データーを変更・削除するたびに索引を書き換えねばならないため、件数が10000件と増えてしまうと索引の書き換えに非常に時間がかかってしまいます。また、データーを削除しても索引に削除コードが書き込まれるだけで、データーそのものは残ってしまうため、定期的にデーターを再編成しないとデーターが肥大化する一方になってしまいます。
この方式は、COBOL言語で標準に搭載され、COBOLで動いている旧式のオフコンやワークステーションでは今でもこの方式でデーターが管理されている事も多いと思います。MS-DOS+16ビット機時代では多く使われました。この頃はハードディスクも100M以下が多く、この方式では1万件程度が限界でしたが、それでもこの頃としては十分事足りていました。
・リレーショナルデーターベース
これまで例にあげた、シーケンシャルファイル、ランダムアクセスファイル、索引編成ファイルは、小規模なデーター管理では十分だったのですが、データーが多くなると処理が重くなり、とても10000件、20000件というデーターを管理することはできません。
そこで登場したのが、リレーショナルデーターベース(RDBMS)です。
データーベースとは、住所録や電話帳のような、データーを管理するためのシステムの事です。例えば、携帯電話には名前・電話番号・メールアドレス等を入力して友達や仕事上で使う連絡先を登録して管理する機能があります。これも一種のデーターベースです。
お店などから届くダイレクトメールには、宛先(住所氏名)が印刷されています。これは、送信側のお店が顧客をコンピューターで管理しているからです。つまり、データーベースを使っているわけです。(小規模なお店では、単にワープロで打ってるだけかもしれませんが・・・)。
シーケンシャルファイル
データーを管理する場合、簡単なのが、テキストファイルとしてエディターに直接手入力することです。そうすれば、エディターの検索機能を使って、欲しい情報をすぐに取り出す事ができます。
例1:テキストファイルでデーターを管理する場合
ちょっと進んでCVSファイルになっていれば、エクセルやアクセスなど、市販のアプリに読み込んでダッグシール印刷等に加工することもできるでしょう。
例2:CVSファイルでデーターを管理する場合
このようなファイルをシーケンシャルファイルといい、特にテキストエディターで簡単に入力/閲覧のできるファイルをプレーンテキストファイルと呼びます。
シーケンシャルファイルの長所は、とにかく扱いが楽なことです。楽というのは、つまり、エディターで開いて検索して該当個所を書き換えればいいわけですから、特にデーターベースの知識のない人でも扱えますし、小規模な顧客管理ではこれでも十分すぎるほどです。
しかしながら、これが顧客が1000件、1000万件と増えてきた場合、一箇所訂正/削除するにも必ず全部のデーターをメモリに読み込んで、検索して、書き換えて、全部のデーターをハードディスクにリライトしなければなりません。
これでは、メモリがいくらあっても足りませんし、読み込み→検索→リライトの作業にとてつもなく時間がかかってしまいます。ましてや、得意先を郵便番号順にソートしたい、とか、売上順にソートしたい、なんて場合にも、全部を読み込んでソートしなければならないため非常に時間がかかります。
そのため、データーをシーケンシャルファイルで管理するのは、データー自体が小規模で、将来的にも増える可能性がない場合のみ、という事になります。
・ランダムアクセスファイル
得意先1件あたりのバイト数(たとえば、256バイト)を決めておいて、2件目なら257バイト目、3件目なら513バイト目・・・という風に、該当個所のみを読み書きする方式があります。これを、ランダムアクセスファイルといいます。
例3:ランダムアクセスファイル
これならば、n件目のデーターを読む場合は、an=(n-1)d + 1バイト目を読み込めば良いことになります。(余談ですが、コンピューターでは普通、計算しやすいように先頭バイトを「0バイト目」と考えますので、2件目は256バイト目、3件目は512バイト目という事になります。)この方式ならば、得意先1000件中の999件目を出したいという場合でも、全てのデーターを読み込むことなく、即座に欲しいデーターを取り出すことができます。
しかし、この方式には欠点がたくさんあります。
欠点1:固定長になってしまう
これはかなり致命的で、一度得意先の情報を256バイトと決めてしまうと、後から仕様変更で256バイトで足りなくなった場合に、データーをコンバートしないといけません。逆に256バイトに満たない場合は無駄に0x00等で埋めなくてはなりません。(これをfillerといいます。)
欠点2:○件目という出し方しかできない
つまり、得意先コードが連番なら良いのですが、1番の次が10000番というわけにはいきません。必ず、1から順に欠番なくコードをわりふらなくてはなりません。また、連番以外ではデーターが出せません。もし、「電話番号 xxxx-xx-xxxxの得意先を出せ」といわれても、全部のデーターを調べなくてはいけません。
このように、欠点だらけの方式ですが、なぜこのような方式があるかというと、昔の8ビットパソコン+フロッピーディスクの時代には、この方式しか大量のデーターを管理するすべがなかったのです。つまり、ディスクの読み書きも、パソコンの処理も低速な機械であっても、この方式であれば、ある程度のデーター管理ができたわけです。
・索引編成ファイル
ランダムアクセスファイルから少し進化したものが、この索引編成ファイルです。
例4:索引編成ファイル
図のように、得意先コード1231は1件目、2231は2件目…という風に、キー(索引)をつくり、まず索引にアクセスしてから該当データーを読み込む方式です。ISAMファイルともいいます。
得意先コードに、1231といった飛び番を使うことができる他、AA001みたいな英文字も扱うことができます。
この方式の欠点は、ランダムアクセスファイルと同様、データーを固定長にしないといけない事です。また、得意先コード以外にも電話番号でも検索できるようにしたい時には電話番号の索引(副キー)も作らねばなりません。
また、データーを変更・削除するたびに索引を書き換えねばならないため、件数が10000件と増えてしまうと索引の書き換えに非常に時間がかかってしまいます。また、データーを削除しても索引に削除コードが書き込まれるだけで、データーそのものは残ってしまうため、定期的にデーターを再編成しないとデーターが肥大化する一方になってしまいます。
この方式は、COBOL言語で標準に搭載され、COBOLで動いている旧式のオフコンやワークステーションでは今でもこの方式でデーターが管理されている事も多いと思います。MS-DOS+16ビット機時代では多く使われました。この頃はハードディスクも100M以下が多く、この方式では1万件程度が限界でしたが、それでもこの頃としては十分事足りていました。
・リレーショナルデーターベース
これまで例にあげた、シーケンシャルファイル、ランダムアクセスファイル、索引編成ファイルは、小規模なデーター管理では十分だったのですが、データーが多くなると処理が重くなり、とても10000件、20000件というデーターを管理することはできません。
そこで登場したのが、リレーショナルデーターベース(RDBMS)です。
リレーショナルデーターベースとは
MicrosoftAcessを扱ったことのある人はわかると思いますが、リレーショナルデーターベースは、データーをテーブルで管理します。
例5:リレーショナルデーターベース

テキストファイルでは、単に得意先コード、得意先名、住所、電話番号をテキストで書いただけですが、リレーショナルデーターベースでは、図のように「列」を定義します。列にはそれぞれ「属性」があり、数字が入る(int型)、文字が入る(text型)、日付が入る(date型)などなどのように、その列にどのような値が入るかを定義しておきます。
データーを代入する時は、それぞれの「列」に対応したデーターを入れます。顧客データー1件分が1行になるわけです。
データーを取り出す時は、必要な列を必要な行数分だけ取り出すことができます。たとえば、電話番号が1234-5678という顧客データーが欲しい場合で、特に得意先の名前だけでいい場合などは、
select tokumei,tel from tokuisaki where tel='1234-5678';
のようにデーターベースに命令します。すると、データーベースの方で、
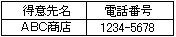
のように、必要なデーターだけを返してくれます。
この方式では、得意先コードだけでなく、郵便番号や電話番号など、さまざまな手がかりでデーターを引き出せるだけでなく、ソートして出したり、合計や平均値を出す、という指定もできるようになります。また、(データーベースシステムにもよりますが)件数が10000件、20000件と増えた場合でも高速にデーターを引き出すことができ、大量のデーターを扱うのに向いています。現在ではこの方式で管理されたデーターベースがほとんどといって良いでしょう。
この方式の欠点は、相当のCPUのパワーと大量のハードディスク容量を必要とする事ですが、相当のCPUパワーといってもペンティアム4、1ギガヘルツ、大量のハードディスクといっても30GB程度で十分でしょう。
先述のランダムアクセスファイルは、8ビットCPUフロッピーベースの頃、索引編成ファイルは旧型オフコンの頃の産物であり、現在市販されているクラスのパソコンで大量データーを管理する時は、リレーショナルデーターベースを使うべきでしょう。
例5:リレーショナルデーターベース
テキストファイルでは、単に得意先コード、得意先名、住所、電話番号をテキストで書いただけですが、リレーショナルデーターベースでは、図のように「列」を定義します。列にはそれぞれ「属性」があり、数字が入る(int型)、文字が入る(text型)、日付が入る(date型)などなどのように、その列にどのような値が入るかを定義しておきます。
データーを代入する時は、それぞれの「列」に対応したデーターを入れます。顧客データー1件分が1行になるわけです。
データーを取り出す時は、必要な列を必要な行数分だけ取り出すことができます。たとえば、電話番号が1234-5678という顧客データーが欲しい場合で、特に得意先の名前だけでいい場合などは、
select tokumei,tel from tokuisaki where tel='1234-5678';
のようにデーターベースに命令します。すると、データーベースの方で、
のように、必要なデーターだけを返してくれます。
この方式では、得意先コードだけでなく、郵便番号や電話番号など、さまざまな手がかりでデーターを引き出せるだけでなく、ソートして出したり、合計や平均値を出す、という指定もできるようになります。また、(データーベースシステムにもよりますが)件数が10000件、20000件と増えた場合でも高速にデーターを引き出すことができ、大量のデーターを扱うのに向いています。現在ではこの方式で管理されたデーターベースがほとんどといって良いでしょう。
この方式の欠点は、相当のCPUのパワーと大量のハードディスク容量を必要とする事ですが、相当のCPUパワーといってもペンティアム4、1ギガヘルツ、大量のハードディスクといっても30GB程度で十分でしょう。
先述のランダムアクセスファイルは、8ビットCPUフロッピーベースの頃、索引編成ファイルは旧型オフコンの頃の産物であり、現在市販されているクラスのパソコンで大量データーを管理する時は、リレーショナルデーターベースを使うべきでしょう。
有料データーベースと無料データーベース
リレーショナルデーターベースソフトで有名なのは、Microsoft Accessです。これは、Windowsパソコンでスタンドアロンで使うのであれば十分なデーターベースを提供してくれます。しかし、サーバー上で動作し、不特定多数の接続に対してデーターの入出力を受け付けるようにするためには、リレーショナルデーターベースサーバーのソフトが必要となります。
リレーショナルデーターベースサーバーには、有料のMicrosoft SQL server、Oracle等と、無料のPostgreSQL、MySQL等があります。
有料のデーターベースサーバーは、ソフトそのものが非常に高価で、さらには接続端末数、同時コネクト数、CPUソケット数、などで定められたライセンス料を支払わねばならず、運用には相当のお金がかかります。
無料のデーターベースサーバーは自力でLinuxサーバーを立てて、tarを展開してコンパイルしインストールするといった作業が必要となります。(RedHatLinuxのRPMを利用する事も可能です。)また、何かわからない事があったら、自力でGoogleで検索して調べるか、エラーメッセージやエラーログを見て解決しなければなりません。
その反面、無料で商用にも利用でき、有料のDBを利用する場合に比較して大幅なコストダウンが可能です。DBサーバーが複数台になるぐらいの大規模なシステムを構築する場合など、無料なのと全てのライセンスを購入するのでは、数百万単位でのコストの差が出る場合すらあります。
なので、無料DBをインストールする知識は、コストダウンへの大きな武器となります。このサイトでも無料DBの1つであるPostgreSQLのインストールについて説明しています。
リレーショナルデーターベースサーバーには、有料のMicrosoft SQL server、Oracle等と、無料のPostgreSQL、MySQL等があります。
有料のデーターベースサーバーは、ソフトそのものが非常に高価で、さらには接続端末数、同時コネクト数、CPUソケット数、などで定められたライセンス料を支払わねばならず、運用には相当のお金がかかります。
無料のデーターベースサーバーは自力でLinuxサーバーを立てて、tarを展開してコンパイルしインストールするといった作業が必要となります。(RedHatLinuxのRPMを利用する事も可能です。)また、何かわからない事があったら、自力でGoogleで検索して調べるか、エラーメッセージやエラーログを見て解決しなければなりません。
その反面、無料で商用にも利用でき、有料のDBを利用する場合に比較して大幅なコストダウンが可能です。DBサーバーが複数台になるぐらいの大規模なシステムを構築する場合など、無料なのと全てのライセンスを購入するのでは、数百万単位でのコストの差が出る場合すらあります。
なので、無料DBをインストールする知識は、コストダウンへの大きな武器となります。このサイトでも無料DBの1つであるPostgreSQLのインストールについて説明しています。
プログラマーとして必要なDBの知識
データーベースの管理者を職業とする人でもない限り、インストールやメンテナンスコマンドの知識までは必要はありませんが、最低限データーベースを読み込んだり書き込んだりする知識は必要となります。
また、データーベースへの問い合わせの知識に乏しいと、1回で済む問い合わせを複数回行ってデーターベースサーバーに負荷をかけてしまう、1行のSQL文で済む計算を、長いプログラムを使って自力で作ってしまう、という事にもなりかねません。
このサイトではプログラマーとして最低限必要なデーターベースの知識を取得する事にしましょう。
また、データーベースへの問い合わせの知識に乏しいと、1回で済む問い合わせを複数回行ってデーターベースサーバーに負荷をかけてしまう、1行のSQL文で済む計算を、長いプログラムを使って自力で作ってしまう、という事にもなりかねません。
このサイトではプログラマーとして最低限必要なデーターベースの知識を取得する事にしましょう。
SQL文
リレーショナルデーターベースでは、SQL文を使ってデーターを読み書きします。
| データーを取り出す | select |
| データーを書き込む | insert |
| データーを更新する | update |
| データーを削除する | delete |
SQL文を使ってデーターをinsert文を使って書き込み、それをselect文で読み出したりします。詳しい書式は、応用編のPostgreSQL入門のところで話をします。
 このページの先頭へ
このページの先頭へ
広告