COBOL入門
このページについて
このページは、パソコン上でMS-DOS上で動作するMicroFocus LEVEL II COBOLおよびMicro Focus COBOL/2の文法に基づいています。
従って、その他のメーカーのCOBOL言語とは文法的に差異がある場合があります。
その他のメーカーのCOBOLをお使いの方にとって、このページの内容に合わない部分もあるかと思いますが、あらかじめご了承の上ご利用ください。
その他のメーカーのCOBOLをお使いの方にとって、このページの内容に合わない部分もあるかと思いますが、あらかじめご了承の上ご利用ください。
DIVISIONとSECTION
COBOLは、まず大きくわけて4つのDIBISION(部)から構成されており、それぞれに、SECTION(節)があります。
| 部 | 節 | |
|---|---|---|
| IDENTIFICATION DIVISION. | 見出し部 | |
| ENVIRONMENT DIVISION. | 環境部 | CONFIGURATION SECTION. |
| INPUT-OUTPUT SECTION. | ||
| DATA DIVISION. | データー部 | FILE SECTION. |
| WORKING-STORAGE SECTION. | ||
| LINKAGE SECTION. | ||
| PROCEDURE DIVISION. | 実行部 | プログラマーが節や段落を設置する。 |
見出し部
見出し部は、プログラムの見出しを書く部です。
こういうのが書式として決まってるのも、COBOLの特徴です。というのも、どの言語でも大抵はコメント行で自由な書式で、プログラムのタイトルや作者名、作成日などを書くものですが、COBOLは非常に形式ばった言語で、作者名、プログラム名、作成日にもちゃんとした書式があります。
PROGRAM-ID. プログラム名.
AUTHOR.作者名.
DATE-WRITTEN.作成日.
環境部
環境部は、さらに環境節と、I-O節に分かれています。
環境節には、ソースコンピューターとオブジェクトコンピューターを記述します。
見出し部は、プログラムの見出しを書く部です。
こういうのが書式として決まってるのも、COBOLの特徴です。というのも、どの言語でも大抵はコメント行で自由な書式で、プログラムのタイトルや作者名、作成日などを書くものですが、COBOLは非常に形式ばった言語で、作者名、プログラム名、作成日にもちゃんとした書式があります。
PROGRAM-ID. プログラム名.
AUTHOR.作者名.
DATE-WRITTEN.作成日.
環境部
環境部は、さらに環境節と、I-O節に分かれています。
環境節には、ソースコンピューターとオブジェクトコンピューターを記述します。
| SOURCE-COMPUTER.プログラム作成に使用したコンピューター名。 OBJECT-COMPUTER.プログラムを実行させる事を想定したコンピューター名。 |
をそれぞれ記述します。しかし、なぜわざわざコンピューター名なんて記述する必要があるのでしょう?(※以下のコラム参照)
| コラム ~ソースコンピューターとオブジェクトコンピューターって?~ もし、Windows上で動くプログラムをWindowsで作る場合は、特に意識する必要はないのですが、サーバー上で動くプログラムを作る場合、サーバーにキーボードとディスプレイをつないで作る場合は稀で、大抵はWindows機で入力したプログラムをサーバーにFTPで送ってコンパイルするなり実行するなりするものと思います。その場合、たとえばソースコンピューターがWindowsでオブジェクトコンピューターがLinuxとなるわけです。 ところで、昔は今のようにLinuxとかWindowsのように全メーカーを意識せずに同じOSが走るのは稀で、日立の○○シリーズといった目的コンピューター用のプログラムは大抵そのコンピューターしか動きません。したがって、そのプログラムが何というコンピューター用に作られたものかというのは、昔は非常に重要な問題だったのでした。 この時代にソースコンピューターと目的コンピューターが別々になるケースとして、大型コンピューター上のプログラムを端末(ワークステーション)で作る場合があります。この場合、ソースコンピューターがそのワークステーションになるわけです。 |
I-O節には、そのプログラムで使うファイルを定義します。
INPUT-OUTPUT SECTION.
FILE-CONTROL.
につづいて、ファイル名やファイルの種類を記述します。詳しくは後ほど説明します。
データー部
データー部とは、つまりデーターセグメントみたいなものです。COBOLでは変数を定義する部と、プログラムを記述する部ははっきりと分かれています。この辺は、アセンブラをやった事のある方の方がわかりやすいかもしれません。
データー部にはファイル節、ワーキング節、リンケージ節があります。ファイル節には、ファイル入出力で使うバッファを宣言し確保します。ワーキング節には、プログラムの実行で使う変数の宣言(メモリーの確保)をします。リンケージ節は外部から呼ばれるプログラム用で、呼び出され側のプログラムと共通のメモリーを使います。
COBOLでは変数の宣言と領域の確保は同時に行われ、全てが固定長で確保されます。詳しくは後ほど説明します。
実行部
ここに、プログラム本体を記述します。コードセグメントみたいなものですね。
INPUT-OUTPUT SECTION.
FILE-CONTROL.
につづいて、ファイル名やファイルの種類を記述します。詳しくは後ほど説明します。
データー部
データー部とは、つまりデーターセグメントみたいなものです。COBOLでは変数を定義する部と、プログラムを記述する部ははっきりと分かれています。この辺は、アセンブラをやった事のある方の方がわかりやすいかもしれません。
データー部にはファイル節、ワーキング節、リンケージ節があります。ファイル節には、ファイル入出力で使うバッファを宣言し確保します。ワーキング節には、プログラムの実行で使う変数の宣言(メモリーの確保)をします。リンケージ節は外部から呼ばれるプログラム用で、呼び出され側のプログラムと共通のメモリーを使います。
COBOLでは変数の宣言と領域の確保は同時に行われ、全てが固定長で確保されます。詳しくは後ほど説明します。
実行部
ここに、プログラム本体を記述します。コードセグメントみたいなものですね。
文法
COBOLはかなり形式にうるさい言語で、記述するカラムまで厳密に決められています。
| カラム | 目的 |
|---|---|
| 1~6 | 行番号 |
| 7 | 区分 |
| 8~72 | 本文 |
| 73~80 | コメント |
1~6カラムは、行番号エリアと決められています。COBOL専用のエディターでは自動的に連番がふられたりしますが、
普通のWindowsのエディタを使うのであれば、何も書かずにタブキーで飛ばしても問題ありません。
7カラムは区分で、ここに*(アスタリスク)をいれると、この行がコメント文だという意味になります。また、Dを入れると、デバッグ行になり、コンパイルはされるが、実行されない行になります。何も書かないと、通常の行になります。-を入れると、前の行の続きという意味になります。
8~72カラムに本文を入れます。という事は、もし73カラム目に文字がかかってしまうと、たとえ予約語や変数の途中であったとしても、そこから先は切られててしまうので注意が必要です。Windowsのエディタを使うのであれば、カラムの表示を注意深く見ます。
73~80カラム目はコメントです、が、こんな狭い空間にコメントなど入れる事はまずないので、ここは通常空白にしておきます。
COBOLでは、予約語がやたら長いわりに、本文を書けるエリアが狭いため、どうしても縦長になります。このため、C言語とかと比べると、1つのプログラムの行数はいやおうなしに長くなります。(アセンブラほどではありませんが)。
COBOLでは、なるべく英文に近い言葉でプログラムできるように考えられたもので、予約語も英語に近いものが多いです。また、文の終わりには.(ピリオド)が必要になります。これも、英文を意識した設計と言えましょう。
7カラムは区分で、ここに*(アスタリスク)をいれると、この行がコメント文だという意味になります。また、Dを入れると、デバッグ行になり、コンパイルはされるが、実行されない行になります。何も書かないと、通常の行になります。-を入れると、前の行の続きという意味になります。
8~72カラムに本文を入れます。という事は、もし73カラム目に文字がかかってしまうと、たとえ予約語や変数の途中であったとしても、そこから先は切られててしまうので注意が必要です。Windowsのエディタを使うのであれば、カラムの表示を注意深く見ます。
73~80カラム目はコメントです、が、こんな狭い空間にコメントなど入れる事はまずないので、ここは通常空白にしておきます。
COBOLでは、予約語がやたら長いわりに、本文を書けるエリアが狭いため、どうしても縦長になります。このため、C言語とかと比べると、1つのプログラムの行数はいやおうなしに長くなります。(アセンブラほどではありませんが)。
COBOLでは、なるべく英文に近い言葉でプログラムできるように考えられたもので、予約語も英語に近いものが多いです。また、文の終わりには.(ピリオド)が必要になります。これも、英文を意識した設計と言えましょう。
ファイルの種類
ファイルは、シーケンシャルファイル、ラインシーケンシャルファイル、ランダムファイル、索引ファイルが指定できます。
| ファイルの種類 | 特徴 |
|---|---|
| シーケンシャルファイル | ファイルを最初から順にベタ読みします。 |
| ラインシーケンシャルファイル | ファイルを行単位で、改行コードで区切って1件ずつ読みます。 |
| ランダムファイル | ファイルを場所を指定してランダムに取り出します。 |
| 索引ファイル | ファイルをキーをつかって呼び出したり、更新したりします。 |
ファイルを定義するためには、SELECT文(SQLではありません)を使います。
| SELECT 内部ファイル名 ASSIGN TO "外部ファイル名" ORGANIZATION ファイルの種類 ACCESS MODE アクセスモード RECOES KEY IS 主キー ALTERNATE RECORDKEY IS 副キー WITH DUPLICATES FILE STATUS IS ファイルステータス. ※細字は省略可。 |
内部ファイル名:このプログラム内で識別するファイルの名前を指定します。Perlでいうところのファイルハンドルみたいなものと思ってください。オープン・クローズ・リードの際に指定します。
外部ファイル名:いわゆるMS-DOSファイル名です。C:\KYU2D\KANMAS.DATみたいに指定します。また、これをPRNにするとプリンタに出力します。
ファイルの種類:シーケンシャルなら、SEQUENTIAL、ラインシーケンシャルなら、LINE SEQUENTIAL、ランダムなら、RELATIVE、索引なら、INDEXEDと書きます。
アクセスモード:最初からベタ読みする場合はSEQUENTIALを指定します。シーケンシャルやラインシーケンシャルは、SEQUENTIALしか指定できません。ランダムに読み書きする場合、RANDOMとします。また、シーケンシャル読みも、ランダム読みも両方する場合、DYNAMICにします。通常、ランダムファイルや索引ファイルは、DYNAMICにしておきます。
ファイルステータス:これを指定しないと、ファイルの読み書きにエラーが生じた場合、エラーメッセージを出してプログラムが強制終了されます。これが指定されると、ファイルの読み書きにエラーが発生しても、プログラムは終了せず、ここにステータスが書き込まれます。ファイルのエラー処理を自前のルーチンで行う場合に指定します。
ファイルステータスは、9タイプで、2バイト指定します。
例)
01 FILE-ST.
03 FST1 PIC 9.
03 FST2 PIC 9.
読み書きにエラーがなければ、FST1に0が入ります。ファイルが存在しなくてオープンできない場合、1が入ります。キーが重複していて書き込めない場合は、2が入ります。ファイルが破損していて読み込めない、もしくは、ハードディスクがいっぱいなど、致命的なエラーがおきた場合、9が入ります。
たいていは、FST1がゼロかどうかで判断すると良いでしょう。
※上記FILE STATUSは、MS-DOSファイルシステム用に作られたMicroFocus系のCOBOLのものです。他システムでは値が異なる場合があります。
主キー:索引ファイルの場合の主キーを指定します。索引ファイルの場合はかならず1個必要です。ランダムファイルの場合、RECORD KEY のかわりに、 RELATIVE KEYと書きます。
副キー:索引ファイルの場合、副キーを設定できます。副キーはいくつでも設定できますが、あまり設定しすぎると更新や削除が非常に遅くなってしまうので、副キーは必要最小限にする必要があります。うしろに、DUPLICATESをつけると、キーの重複が許されるようになります。キーの重複が許されるのは副キーだけで、主キーには許されません。
※COBOLでは、ISなどのBe動詞や、WITHなどの前置詞は、書いても書かなくても良い事になっています。(算術式では必須)。ただし、文章の流れからいくと、Be動詞や前置詞はあった方が「しっくりいく」ので、書く人の方が多いです。
外部ファイル名:いわゆるMS-DOSファイル名です。C:\KYU2D\KANMAS.DATみたいに指定します。また、これをPRNにするとプリンタに出力します。
ファイルの種類:シーケンシャルなら、SEQUENTIAL、ラインシーケンシャルなら、LINE SEQUENTIAL、ランダムなら、RELATIVE、索引なら、INDEXEDと書きます。
アクセスモード:最初からベタ読みする場合はSEQUENTIALを指定します。シーケンシャルやラインシーケンシャルは、SEQUENTIALしか指定できません。ランダムに読み書きする場合、RANDOMとします。また、シーケンシャル読みも、ランダム読みも両方する場合、DYNAMICにします。通常、ランダムファイルや索引ファイルは、DYNAMICにしておきます。
ファイルステータス:これを指定しないと、ファイルの読み書きにエラーが生じた場合、エラーメッセージを出してプログラムが強制終了されます。これが指定されると、ファイルの読み書きにエラーが発生しても、プログラムは終了せず、ここにステータスが書き込まれます。ファイルのエラー処理を自前のルーチンで行う場合に指定します。
ファイルステータスは、9タイプで、2バイト指定します。
例)
01 FILE-ST.
03 FST1 PIC 9.
03 FST2 PIC 9.
読み書きにエラーがなければ、FST1に0が入ります。ファイルが存在しなくてオープンできない場合、1が入ります。キーが重複していて書き込めない場合は、2が入ります。ファイルが破損していて読み込めない、もしくは、ハードディスクがいっぱいなど、致命的なエラーがおきた場合、9が入ります。
たいていは、FST1がゼロかどうかで判断すると良いでしょう。
※上記FILE STATUSは、MS-DOSファイルシステム用に作られたMicroFocus系のCOBOLのものです。他システムでは値が異なる場合があります。
主キー:索引ファイルの場合の主キーを指定します。索引ファイルの場合はかならず1個必要です。ランダムファイルの場合、RECORD KEY のかわりに、 RELATIVE KEYと書きます。
副キー:索引ファイルの場合、副キーを設定できます。副キーはいくつでも設定できますが、あまり設定しすぎると更新や削除が非常に遅くなってしまうので、副キーは必要最小限にする必要があります。うしろに、DUPLICATESをつけると、キーの重複が許されるようになります。キーの重複が許されるのは副キーだけで、主キーには許されません。
※COBOLでは、ISなどのBe動詞や、WITHなどの前置詞は、書いても書かなくても良い事になっています。(算術式では必須)。ただし、文章の流れからいくと、Be動詞や前置詞はあった方が「しっくりいく」ので、書く人の方が多いです。
変数の宣言
変数は、データー部ワーキング節で宣言します。
COBOLの変数は『集団名』と『要素』というのを非常に意識した作りになっています。すべての変数が、C言語でいうところの、『struct構造体』になっていると考えると良いかもしれません。
変数を宣言する場合、
レベル 変数名 PIC タイプ(桁数) 格納形式.
という風に書きます。
・レベルとは
例えば、
01 YN PIC X(01).
という場合『01レベルの、YNという名前の変数を、Xタイプで1桁確保する』という意味になります。レベルとは、『その変数が、集団の中のどのレベルにあるか』という意味で、変数同士の上下関係を表しています。
01 LOC.
03 LOC1 PIC 99.
03 LOC2 PIC 99.
という場合、LOCという集団項目のなかの要素として、LOC1と、LOC2という変数があるという意味になります。この場合、人間の目からみると、集団項目であるLOCと、その要素である、LOC1、LOC2は、位置をずらして書いている事で、その上下関係を把握できますが、コンパイラは位置ではなく、レベル番号で判断します。
つまり、レベル番号03の変数は、その前の01レベルの変数の要素だという意味になります。また、01レベルは一番の親という意味になります。
もし、
01 LOC.
03 LOC1 PIC 99.
03 LOC2.
05 LOC2-1 PIC 9.
05 LOC2-2 PIC 9.
の場合、05レベルである「LOC2-1とLOC2-2」が、03レベルであるLOC2という変数の要素であり、そのLOC2は、01レベルであるLOCという変数の要素であるという事になります。このように、集団変数の上下関係は、人間の目でわかるように、位置をずらして記述し、コンパイラにわかるように、レベル番号をつけるという事いなります。
注意!!
01 LOC.
03 LOC1.
01 LOC2.
のように、レベル番号を間違えてしまった場合、人間の目からみれば、ズラして書いたLOC2が、LOCの要素のように見えますが、コンパイラは、01と書かれたLOC2は、単独項目(つまり、LOCと同じレベル)と見なされます。コンパイラエラーにはなりませんが、実行させると期待通りの動作はしません。この場合、プログラム作成者本人は先入観で01とある所を自身で03と読み替えてしまうため、なかなか発見が困難なバグとなります。
変数名
変数名は、A~Z、0~9の数字が使えます。ただし、
COBOLの変数は『集団名』と『要素』というのを非常に意識した作りになっています。すべての変数が、C言語でいうところの、『struct構造体』になっていると考えると良いかもしれません。
変数を宣言する場合、
レベル 変数名 PIC タイプ(桁数) 格納形式.
という風に書きます。
・レベルとは
例えば、
01 YN PIC X(01).
という場合『01レベルの、YNという名前の変数を、Xタイプで1桁確保する』という意味になります。レベルとは、『その変数が、集団の中のどのレベルにあるか』という意味で、変数同士の上下関係を表しています。
01 LOC.
03 LOC1 PIC 99.
03 LOC2 PIC 99.
という場合、LOCという集団項目のなかの要素として、LOC1と、LOC2という変数があるという意味になります。この場合、人間の目からみると、集団項目であるLOCと、その要素である、LOC1、LOC2は、位置をずらして書いている事で、その上下関係を把握できますが、コンパイラは位置ではなく、レベル番号で判断します。
つまり、レベル番号03の変数は、その前の01レベルの変数の要素だという意味になります。また、01レベルは一番の親という意味になります。
もし、
01 LOC.
03 LOC1 PIC 99.
03 LOC2.
05 LOC2-1 PIC 9.
05 LOC2-2 PIC 9.
の場合、05レベルである「LOC2-1とLOC2-2」が、03レベルであるLOC2という変数の要素であり、そのLOC2は、01レベルであるLOCという変数の要素であるという事になります。このように、集団変数の上下関係は、人間の目でわかるように、位置をずらして記述し、コンパイラにわかるように、レベル番号をつけるという事いなります。
注意!!
01 LOC.
03 LOC1.
01 LOC2.
のように、レベル番号を間違えてしまった場合、人間の目からみれば、ズラして書いたLOC2が、LOCの要素のように見えますが、コンパイラは、01と書かれたLOC2は、単独項目(つまり、LOCと同じレベル)と見なされます。コンパイラエラーにはなりませんが、実行させると期待通りの動作はしません。この場合、プログラム作成者本人は先入観で01とある所を自身で03と読み替えてしまうため、なかなか発見が困難なバグとなります。
変数名
変数名は、A~Z、0~9の数字が使えます。ただし、
- 大文字と小文字は区別しない。AAAとaaaとAaaは同じ変数と見なされる。
- 数字が先頭の変数名は使うことができない
- _(アンダーバー)は使うことができない
アンダーバーが使えないので、かわりに、-(マイナス)を使います。他の言語では、大抵は A-B のように、-記号は(マイナス)という算術記号として扱われるのですが、COBOLでは-記号は単なるハイフンとして扱われ、変数名に使うことができます。もし、COBOLで『-』を『マイナス』として使う時は、
A - B
のように、空白をあけることで、ハイフンとマイナス記号の意味を区別しています。
COBOLで中学生程度の英単語を変数名で使うのは避けた方が無難です。なぜなら、COBOLでは予約語があまりに多く、中学生程度の英単語は、たいてい何かしらの予約語とぶつかります。 COBOLでは変数名は、ローマ字表記の日本語を使うか、複数の単語をハイフンで繋いで組み合わせる等で既存の英単語と区別するようにしましょう。
例)
01 STATUS PIC 9(01).
は、『STATUS』が予約語なので使うことができません。この場合、『FILE-STATUS』とかして名前を長くするか、『SUTEITASU』みたいに日本語にする。
A - B
のように、空白をあけることで、ハイフンとマイナス記号の意味を区別しています。
COBOLで中学生程度の英単語を変数名で使うのは避けた方が無難です。なぜなら、COBOLでは予約語があまりに多く、中学生程度の英単語は、たいてい何かしらの予約語とぶつかります。 COBOLでは変数名は、ローマ字表記の日本語を使うか、複数の単語をハイフンで繋いで組み合わせる等で既存の英単語と区別するようにしましょう。
例)
01 STATUS PIC 9(01).
は、『STATUS』が予約語なので使うことができません。この場合、『FILE-STATUS』とかして名前を長くするか、『SUTEITASU』みたいに日本語にする。
| コラム ~C系の言語とCOBOLとの習慣の違い~ C系の言語では、予約語も少なく、特にPerlやPHPでは変数の頭に$をつけて区別するため、予約語とのバッティングを気にする必要がありません。なので、変数名にも、a、b、x、yなど一文字がよく使われます。C系ではあまり長い変数名は美しくないプログラムの代表のように言われます。 しかし、COBOLでは1文字の変数名はまず使いません。それどこか、短い変数名にすると予約後とかなりぶつかるため、MAIN-FLUG-TABLEのように、相当長い変数名が使われることが多いです。また、COBOLでは変数名にアンダーバーが使えずハイフンが使える事もあって、複数の単語をハイフンで繋いだ変数名がよく使われます。 もし、C系の言語で長い変数名を使う人がいたら、その人はCOBOL出身者かもしれません。 |
PIC
PICは、PICTUREの略で(実際にPICTUREと書いても良い)、『領域を描く』という意味です。要するに、メモリを確保します。
タイプ
MOVEされた値がどのような形式でメモリーに格納されるかを指定します。 C言語でいうところのprintfのフォーマット指定子みたいなものだと思ってください。
PICは、PICTUREの略で(実際にPICTUREと書いても良い)、『領域を描く』という意味です。要するに、メモリを確保します。
タイプ
MOVEされた値がどのような形式でメモリーに格納されるかを指定します。 C言語でいうところのprintfのフォーマット指定子みたいなものだと思ってください。
| タイプ | 意味 | 目的 |
|---|---|---|
| 9 | 数値。桁のない部分はゼロで埋まる。 | 計算用 |
| V | 小数点の位置を示す。メモリは確保しない。 | |
| X | 文字。 | 表示用 |
| N | 全角文字。 | |
| Z | 数値。桁のない部分は空白になる。 | |
| - | 数値。桁のない部分は空白になる。左端に-か空白が入る。 | |
| + | 数値。桁のない部分は空白になる。左端に-か+が入る。 | |
| * | 数値。桁のない部分には、*が入る。 | |
| B | 空白が挿入される。 | |
| , | カンマが挿入される。 | |
| / | スラッシュが挿入される。 | |
| . | ピリオドが挿入される。 |
・9タイプ(アンパック形式)
9タイプは主に計算用ですが、USAGE DISPLAY句を指定する(あるいはUSAGE句を指定しない)場合、999999999(もしくは9(09))は、000000001みたいに、最大桁の左側は0で埋められた右詰の形式(キャラクターコード0x30~0x39)で格納されます。PerlやPHPでいうところの、sprintfの%09dみたいなものです。
表示用としてはあまり使いにくい形式ですが、COBOLのファイルはランダムファイルにしろISAMファイルにしろ固定長であり、出力ファイルをプレーンテキストにするため数値型をアンパックの9タイプとして確保する事があります。
また、JCA手順で伝送する時にはバイナリが使えないので、数値はアンパックの9タイプで確保します。例えば、チェーンストアからJCA手順で受注データーを受信する時に、仕様書には9(09)みたいな事が書いてあると思います。今でも、古いシステムから出力されたファイルを現在のLinuxサーバーに取り込む際に古いシステムの仕様書に9(09)とか書いてあると思います。
・Zタイプ
Zは有効数字の左側を空白に置き換えます。つまり、ZZZなら、[空白][空白]1みたいに右詰の数値になります。これをZZZではなく、ZZ9とすると、ゼロだった場合にオール空白ではなく、右詰めの0になります。
Zタイプはしばしば,(カンマ)と組み合わせて使われます。ZZZ,ZZ9みたいに3桁おきにカンマを入れれば、1,000という風に、PHPでいうところのnumber_formatみたいな形式で表示させる事ができます。もっとも、右詰になるので厳密にはnumber_formatとは異なりますが。
Zタイプではマイナス符号を表示させる事ができないため、伝票の入力や印刷などの業務系ではZよりも-を使う場合が多いです。
・-タイプ
Zタイプと似ていますが、マイナスタイプの場合、マイナス符号を表示させる事ができます。ACCEPTならマイナスを入力する事ができるようになります。
注意して欲しいのはマイナスタイプの場合、一番左側にはマイナス記号か空白しか入らないので、 PIC -----.に-10000を入れると、-0というヘンな表示になってしまうという事です。なので、 マイナスが入る可能性のある場合には、予想される最大桁数よりも1桁多めに取らなくてはなりません。
・サンプル
9タイプは主に計算用ですが、USAGE DISPLAY句を指定する(あるいはUSAGE句を指定しない)場合、999999999(もしくは9(09))は、000000001みたいに、最大桁の左側は0で埋められた右詰の形式(キャラクターコード0x30~0x39)で格納されます。PerlやPHPでいうところの、sprintfの%09dみたいなものです。
表示用としてはあまり使いにくい形式ですが、COBOLのファイルはランダムファイルにしろISAMファイルにしろ固定長であり、出力ファイルをプレーンテキストにするため数値型をアンパックの9タイプとして確保する事があります。
また、JCA手順で伝送する時にはバイナリが使えないので、数値はアンパックの9タイプで確保します。例えば、チェーンストアからJCA手順で受注データーを受信する時に、仕様書には9(09)みたいな事が書いてあると思います。今でも、古いシステムから出力されたファイルを現在のLinuxサーバーに取り込む際に古いシステムの仕様書に9(09)とか書いてあると思います。
・Zタイプ
Zは有効数字の左側を空白に置き換えます。つまり、ZZZなら、[空白][空白]1みたいに右詰の数値になります。これをZZZではなく、ZZ9とすると、ゼロだった場合にオール空白ではなく、右詰めの0になります。
Zタイプはしばしば,(カンマ)と組み合わせて使われます。ZZZ,ZZ9みたいに3桁おきにカンマを入れれば、1,000という風に、PHPでいうところのnumber_formatみたいな形式で表示させる事ができます。もっとも、右詰になるので厳密にはnumber_formatとは異なりますが。
Zタイプではマイナス符号を表示させる事ができないため、伝票の入力や印刷などの業務系ではZよりも-を使う場合が多いです。
・-タイプ
Zタイプと似ていますが、マイナスタイプの場合、マイナス符号を表示させる事ができます。ACCEPTならマイナスを入力する事ができるようになります。
注意して欲しいのはマイナスタイプの場合、一番左側にはマイナス記号か空白しか入らないので、 PIC -----.に-10000を入れると、-0というヘンな表示になってしまうという事です。なので、 マイナスが入る可能性のある場合には、予想される最大桁数よりも1桁多めに取らなくてはなりません。
・サンプル
サンプル1
0を代入した場合
0を代入した場合
DATA DIVISION. WORKING-STORAGE SECTION. 01 HENSU1 PIC 9(09). 01 HENSU2 PIC S9(09). 01 HENSU3 PIC ZZZ,ZZZ,ZZ9. 01 HENSU4 PIC ZZZ,ZZZ,ZZZ. 01 HENSU5 PIC ---,---,--9. 01 HENSU6 PIC ---,---,---. PROCEDURE DIVISION. DISPLAY SPACE. MOVE 0 TO HENSU1. MOVE 0 TO HENSU2. MOVE 0 TO HENSU3. MOVE 0 TO HENSU4. MOVE 0 TO HENSU5. MOVE 0 TO HENSU6. DISPLAY HENSU1 AT 0101. DISPLAY HENSU2 AT 0201. DISPLAY HENSU3 AT 0301. DISPLAY HENSU4 AT 0401. DISPLAY HENSU5 AT 0501. DISPLAY HENSU6 AT 0601. ACCEPT YN AT 0701.
サンプル1の実行結果
サンプル1の実行結果
000000000
000000000
0
0
ちょっとWebだとスペースの数がわかりにくいですが、なんとか感じはつかめていただけましたでしょうか?Zタイプや-タイプは、1桁目をZや-にするか、9にするかで、0を代入した時の結果に違いが出ます。1桁目だけ9なら、0を代入した時に1桁目だけに0が入ります。
サンプル2
桁めいっぱいに代入した場合
サンプル2
桁めいっぱいに代入した場合
DATA DIVISION. WORKING-STORAGE SECTION. 01 HENSU1 PIC 9(09). 01 HENSU2 PIC S9(09). 01 HENSU3 PIC ZZZ,ZZZ,ZZ9. 01 HENSU4 PIC ZZZ,ZZZ,ZZZ. 01 HENSU5 PIC ---,---,--9. 01 HENSU6 PIC ---,---,---. PROCEDURE DIVISION. DISPLAY SPACE. MOVE -999999999 TO HENSU1. MOVE -999999999 TO HENSU2. MOVE -999999999 TO HENSU3. MOVE -999999999 TO HENSU4. MOVE -999999999 TO HENSU5. MOVE -999999999 TO HENSU6. DISPLAY HENSU1 AT 0101. DISPLAY HENSU2 AT 0201. DISPLAY HENSU3 AT 0301. DISPLAY HENSU4 AT 0401. DISPLAY HENSU5 AT 0501. DISPLAY HENSU6 AT 0601. ACCEPT YN AT 0701.
サンプル2の実行結果
999999999 99999999y 999,999,999 999,999,999 -99,999,999 -99,999,999
マイナスタイプを9桁指定すると8桁で桁あふれするので注意してください。また、9タイプで符号尽き(S)を指定すると、1桁目が文字化けしますが、これは1桁目に符号ビットがつくためです。
サンプル3
桁に余裕がある場合
サンプル3
桁に余裕がある場合
DATA DIVISION. WORKING-STORAGE SECTION. 01 HENSU1 PIC 9(09). 01 HENSU2 PIC S9(09). 01 HENSU3 PIC ZZZ,ZZZ,ZZ9. 01 HENSU4 PIC ZZZ,ZZZ,ZZZ. 01 HENSU5 PIC ---,---,--9. 01 HENSU6 PIC ---,---,---. PROCEDURE DIVISION. DISPLAY SPACE. MOVE -100 TO HENSU1. MOVE -100 TO HENSU2. MOVE -100 TO HENSU3. MOVE -100 TO HENSU4. MOVE -100 TO HENSU5. MOVE -100 TO HENSU6. DISPLAY HENSU1 AT 0101. DISPLAY HENSU2 AT 0201. DISPLAY HENSU3 AT 0301. DISPLAY HENSU4 AT 0401. DISPLAY HENSU5 AT 0501. DISPLAY HENSU6 AT 0601. ACCEPT YN AT 0701.
サンプル3の実行結果
000000100
00000010p
100
100
-100
-100
数値は基本的に右詰で入りますが、9タイプでは有効数字の左側は0で埋められます。また、負の数が入った場合、符号尽き(S)が指定されていれば1桁目に符号ビットが立ち、そのまま表示させると1桁目が文字化けします。
Zタイプやマイナスタイプが指定されている場合、有効数字の左側は空白になります。カンマの部分も有効数字の左側なら空白になります。Zタイプではマイナスを入れてもマイナス符号はつきません。
| コラム 100をMOVEしたら10,000になる!? | |
 |
起こった事をありのままに話すぜ 俺は確かに100をMOVEしたら100になると書いたんだ だが、OKWaveに晒された後確認したら、 「100をMOVEしたら10,000になる」と書いてあったんだ な…何を言ってるのかわからねーと思うが おれも何をされたのかわからなかった… 頭がどうにかなりそうだった… 催眠術だとか超スピードだとか そんなチャチなもんじゃあ断じてねえ もっと恐ろしいものの片鱗を味わったぜ… |
格納形式
数値変数をどういう形式で格納するかを記載します。
無指定、もしくは、USAGE DISPLAYと書くと、数値変数はすべてキャラクターコードで格納されます。つまり、123を格納する場合、16進数で31H 32H 33Hという風に3バイト使って格納されます。(余った左の部分には、30Hが入ります)。
S9(09)という風に、Sを指定すると符号付の変数になります。符号付変数にマイナスを入れた場合、1番右の桁が40Hくりあげた(ゲタをはいた)形で格納されます。(マイナス1は、31Hではなく、71Hという風に)
COMP-3を記述すると、数値変数は4ビットで1桁を格納し、最後の4ビットに符号が入ります。たとえば、123を格納する場合、12H 3CHという風に格納されます。最後のCがプラスで、Dならマイナスという意味になります。COBOLでは慣習的に大抵の計算用変数は、この形式にします。
COMPまたは、BINARYを記述すると、数値はバイナリで格納されます。実際には16進数で格納されます。Perlでバイナリにパックした場合はpackを使いますが、COBOLではCOMPと指定された変数に代入する事でバイナリにパックされます。例えば、123を代入すると7BHが格納されます。アセンブラ言語とのリンクをする場合などに使います。
その他
BLANK WHEN ZERO.を記述すると、ゼロはすべて空白になります。たとえば、PIC 99/99/99 BLANK WHEN ZERO.と宣言した変数に0を代入すると、結果は空白になります。9タイプで普段は上の桁をゼロでうめるが、ゼロの場合だけ空白にしたい時に使います。
変数の再定義
同じメモリに、複数の名前(別の構造)を定義する事ができます。C言語でいうところの、unionのようなものです。
レベル 新しい変数名 REDEFINES 置き換え元変数名.
レベルは、置き換え元変数と同じにします。新しい変数名に続いてREDEFINESと書いた後、置き換え元の変数名を記述します。
例)
01 変数1 PIC --------9V99.
01 変数2 REDEFINES 変数1.
03 変数2-1 PIC X(09).
03 変数2-2 PIC X(02).
この場合、変数1の整数部を変数2-1、変数1の小数部を変数2-2に再定義しています。これにより、変数1の小数部分がゼロならば、空白に置き換えるという事ができるようになります。ターンアラウンド2型伝票に印刷する場合、小数点以下が00なら空白に置き換えなければならないので、このように定義します。変数を再定義する場合、必ず置き換え元変数を定義した直後に行わなくてはなりません。
FILLER
メモリは確保するが、特に名前は付けない場合には、FILLERと記載します。
例)
FD SHAMAS.
01 SHAREC.
03 SHA1 PIC 9(05).
:
03 SHA17 PIC X(10).
03 FILLER PIC X(256).
の場合、社員マスターの最後に予備としてとりあえず256バイト確保しておきます。この場合、領域だけ確保するだけなので、名前をつける必要はありません。そこで、名前の部分を、FILLERと記述します。なぜこのような事をするかと言えば、あとで項目を追加する場合に必要になるからです。
COBOLでは、乱編成ファイル・索引編成ファイルといった、ランダムアクセスを要するファイルは固定長で定義しなければなりません。PostgreSQLとかだと、7以降であればalter tableで簡単にフィールドを追加できますが、COBOLの索引編成ファイルではそうもいかないので、FILLERとしてあらかじめ予備領域を取っておいて、後から項目が増えた場合はFILLERを削ってその分を新しい領域にします。
ハードディスクがまだなかった(あっても10メガ程度で数十万円してた頃)は、フロッピーディスク(3.5インチ/5インチ/8インチ)にデーターを記録していたのですが、フロッピーディスクには慣習として1レコード長がフロッピーディスクのセクタ長と同じになるようにFILLERで調整していました。(つまり、PC9801なら1024バイト、J-3100なら512バイトという風に)
配列
COBOLでも配列変数を使う事ができます。いわゆる、BASICでいうところのDIMで、C言語でいうところの、a[ ] で、Perlでいうところの@変数名で、PHPでいうところのarray()です。
例)
01FLG-1 PIC 9(01) OCCURS 10.
のようにして、FLG-1という数値1桁の変数を10個確保します。FLG-1が10回occur(発生)するという意味です。これを使う場合、
FLG-1(1)
のように、丸カッコをつけて配列の要素を指定します。他の言語に慣れた人が見ると、丸カッコがあると関数みたいですが、そうではありません。また、C言語のように、ゼロからはじまるのではなく、1からはじまるので注意してください。
もし、配列の添字として、0もしくは、宣言した数より大きい数を指定した場合、コンパイルはそのまま通ってしまいますが、実行時にエラーになります。
二次元配列
二次元配列を使う場合、レベル番号で区別します。
例)
01 FLG1 OCCURS 5.
03 FLG2 PIC 9(01) OCCURS 10.
の場合、『FLG2という名前の10個の配列』をもつ集団『FLG1』が、5個あるという意味になります。
使う場合、下の階層の変数名につづき、カッコでくくって、(上の階層の位置,下の階層の位置)という風に書きます。
たとえば、
FLG2(1, 1)
とした場合、FLG1の1番目の階層の中の、FLG2の1番目項目という意味になります。この場合、2次元目は10個確保してありますが、FLG2(1,11)のように2次元目の添字がオーバーしてしまった場合は、エラーにはならずにFLG2(2,1)つまり1次元目が次の変数の先頭が書き換わってしまうので注意が必要です。
数値変数をどういう形式で格納するかを記載します。
無指定、もしくは、USAGE DISPLAYと書くと、数値変数はすべてキャラクターコードで格納されます。つまり、123を格納する場合、16進数で31H 32H 33Hという風に3バイト使って格納されます。(余った左の部分には、30Hが入ります)。
S9(09)という風に、Sを指定すると符号付の変数になります。符号付変数にマイナスを入れた場合、1番右の桁が40Hくりあげた(ゲタをはいた)形で格納されます。(マイナス1は、31Hではなく、71Hという風に)
COMP-3を記述すると、数値変数は4ビットで1桁を格納し、最後の4ビットに符号が入ります。たとえば、123を格納する場合、12H 3CHという風に格納されます。最後のCがプラスで、Dならマイナスという意味になります。COBOLでは慣習的に大抵の計算用変数は、この形式にします。
COMPまたは、BINARYを記述すると、数値はバイナリで格納されます。実際には16進数で格納されます。Perlでバイナリにパックした場合はpackを使いますが、COBOLではCOMPと指定された変数に代入する事でバイナリにパックされます。例えば、123を代入すると7BHが格納されます。アセンブラ言語とのリンクをする場合などに使います。
その他
BLANK WHEN ZERO.を記述すると、ゼロはすべて空白になります。たとえば、PIC 99/99/99 BLANK WHEN ZERO.と宣言した変数に0を代入すると、結果は空白になります。9タイプで普段は上の桁をゼロでうめるが、ゼロの場合だけ空白にしたい時に使います。
変数の再定義
同じメモリに、複数の名前(別の構造)を定義する事ができます。C言語でいうところの、unionのようなものです。
レベル 新しい変数名 REDEFINES 置き換え元変数名.
レベルは、置き換え元変数と同じにします。新しい変数名に続いてREDEFINESと書いた後、置き換え元の変数名を記述します。
例)
01 変数1 PIC --------9V99.
01 変数2 REDEFINES 変数1.
03 変数2-1 PIC X(09).
03 変数2-2 PIC X(02).
この場合、変数1の整数部を変数2-1、変数1の小数部を変数2-2に再定義しています。これにより、変数1の小数部分がゼロならば、空白に置き換えるという事ができるようになります。ターンアラウンド2型伝票に印刷する場合、小数点以下が00なら空白に置き換えなければならないので、このように定義します。変数を再定義する場合、必ず置き換え元変数を定義した直後に行わなくてはなりません。
FILLER
メモリは確保するが、特に名前は付けない場合には、FILLERと記載します。
例)
FD SHAMAS.
01 SHAREC.
03 SHA1 PIC 9(05).
:
03 SHA17 PIC X(10).
03 FILLER PIC X(256).
の場合、社員マスターの最後に予備としてとりあえず256バイト確保しておきます。この場合、領域だけ確保するだけなので、名前をつける必要はありません。そこで、名前の部分を、FILLERと記述します。なぜこのような事をするかと言えば、あとで項目を追加する場合に必要になるからです。
COBOLでは、乱編成ファイル・索引編成ファイルといった、ランダムアクセスを要するファイルは固定長で定義しなければなりません。PostgreSQLとかだと、7以降であればalter tableで簡単にフィールドを追加できますが、COBOLの索引編成ファイルではそうもいかないので、FILLERとしてあらかじめ予備領域を取っておいて、後から項目が増えた場合はFILLERを削ってその分を新しい領域にします。
ハードディスクがまだなかった(あっても10メガ程度で数十万円してた頃)は、フロッピーディスク(3.5インチ/5インチ/8インチ)にデーターを記録していたのですが、フロッピーディスクには慣習として1レコード長がフロッピーディスクのセクタ長と同じになるようにFILLERで調整していました。(つまり、PC9801なら1024バイト、J-3100なら512バイトという風に)
配列
COBOLでも配列変数を使う事ができます。いわゆる、BASICでいうところのDIMで、C言語でいうところの、a[ ] で、Perlでいうところの@変数名で、PHPでいうところのarray()です。
例)
01FLG-1 PIC 9(01) OCCURS 10.
のようにして、FLG-1という数値1桁の変数を10個確保します。FLG-1が10回occur(発生)するという意味です。これを使う場合、
FLG-1(1)
のように、丸カッコをつけて配列の要素を指定します。他の言語に慣れた人が見ると、丸カッコがあると関数みたいですが、そうではありません。また、C言語のように、ゼロからはじまるのではなく、1からはじまるので注意してください。
もし、配列の添字として、0もしくは、宣言した数より大きい数を指定した場合、コンパイルはそのまま通ってしまいますが、実行時にエラーになります。
二次元配列
二次元配列を使う場合、レベル番号で区別します。
例)
01 FLG1 OCCURS 5.
03 FLG2 PIC 9(01) OCCURS 10.
の場合、『FLG2という名前の10個の配列』をもつ集団『FLG1』が、5個あるという意味になります。
使う場合、下の階層の変数名につづき、カッコでくくって、(上の階層の位置,下の階層の位置)という風に書きます。
たとえば、
FLG2(1, 1)
とした場合、FLG1の1番目の階層の中の、FLG2の1番目項目という意味になります。この場合、2次元目は10個確保してありますが、FLG2(1,11)のように2次元目の添字がオーバーしてしまった場合は、エラーにはならずにFLG2(2,1)つまり1次元目が次の変数の先頭が書き換わってしまうので注意が必要です。
実行部
実行部は、PROCEDURE DIVISIONと言い、プログラム本体をここに記述します。実行部は、それぞれ『節』『段落』にわかれています。
| 節1 段落1 段落2 節2 段落3 段落4 節3 段落5 : : : : |
ここで、『節』は、具体的には SECTION といい、「FREAD1
SECTION」みたいに記述します。C言語でいうところの「関数」、BASICでいうところの「ルーチン」です。また、段落というのは、いわゆる「ラベル」です。GO TOやPERFORMなどの分岐命令で使います。
条件判断
COBOLでは、条件判断に、IF、EVALUETE、PERFORMがあります。
IF
どの言語にも(多分)あるIFです。
IF
どの言語にも(多分)あるIFです。
| 例) IF 条件 (文1) ELSE (文2) END-IF. 条件が真なら(文1)を実行します。条件が偽なら(文2)を実行します。 |
END-IFはLEVEL II COBOLでは使う事ができません。
EVALUATE~WHEN
いわゆる、C言語でいうところの、switch~caseです。この命令はLEVEL II COBOLでは使う事ができません。
いわゆる、C言語でいうところの、switch~caseです。この命令はLEVEL II COBOLでは使う事ができません。
| 例) EVALUATE 変数 WHEN 1 (文1) WHEN 2 (文2) OTHERS (文3) END-EVALUATE. 変数が、1なら(文1)を実行し、2なら(文2)を実行します。それ以外なら、(文3)を実行します。 |
PERFORM
PERFORMは、パフォーマンスのパフォームで、「遂行する」という意味です。COBOLのPERFORMには色々な使い方があり、いわゆるC系でいうところの、forループにも使えますし、whileループの意味にもなります。さらに、サブルーチンコールの意味にもなります。
LEVEL II COBOLではサブルーチンコールしか使う事ができません。
PERFORMは、パフォーマンスのパフォームで、「遂行する」という意味です。COBOLのPERFORMには色々な使い方があり、いわゆるC系でいうところの、forループにも使えますし、whileループの意味にもなります。さらに、サブルーチンコールの意味にもなります。
LEVEL II COBOLではサブルーチンコールしか使う事ができません。
| 例1)いわゆるforループとして使う場合 例えば、PHPで書くとしたら for (カウンター=初期値; 条件; 式) みたいに書くと、1ループ毎に式を実行しながら条件が真である限りループしますが、それをCOBOLでは以下のように書きます。 PERFORM VARYING カウンター FROM 初期値 BY 上昇値 UNTIL (条件) (文) END-PERFORM. カウンターで示された変数を、初期値から、1回ループするごとに上昇値を加算し、(条件)が【偽】である限りループします。この場合のUNTILは、条件が真になる『まで』と解釈するのが良いでしょう。 例2)いわゆるwhileとして使う場合 例えば、PHPで書くとしたら while (条件)と書くものを、COBOLでは次のように書きます。 PERFORM UNTIL (条件) (文) END-PERFORM. (条件)が、【偽】である限りループします。この場合も、条件が【真】になる『まで』ループすると解釈します。 ※サブルーチンコールとして使う方法は後述します。 |
演算子
演算子には「代入」「加算」「減算」「除算」「乗算」があります。
代入
MOVE 変数 1 TO 変数2 変数3 変数4.....
変数1の値を、変数2、変数3、変数4....に代入します。この場合、変数には集団項目を使うことができます。また、表示用変数から計算用変数へ、または、その逆ができます。
加算
ADD 変数1 TO 変数2 変数3 変数4....
変数1の値を、変数2、変数3、変数4...に追加します。変数はすべて計算用として宣言します。
減算
SUBTRACT 変数1 FROM 変数2 変数3 変数4....
変数1の値を、変数2、変数3、変数4...から引きます。変数はすべて計算用として宣言します。
除算
DIVIDE 変数1 BY 変数2 GIVING 変数3 REMAINDER 変数4.
変数1を変数2でわって、商を変数3、あまりを変数4に入れます。変数はすべて計算用として宣言します。変数3に小数点が定義された場合、あまりは、さらにその先の小数点以下になります。
乗算
MULTIPLY 変数1 BY 変数2 GIVING 変数3.
変数1と変数2をかけて、変数3に代入します。変数はすべて計算用として宣言します。
COMPUTE演算子
COMPUTE 変数1 (ROUNDED) = (式).
(式)の結果を、変数1に入れます。変数1は、表示用でも計算用でもかまいませんが、計算用が望ましいようです。コンパイラによっては、変数1が表示用だとバグって変な数になる事があります。
(式)には、+-*/が使えますが、注意して欲しいのは、必ず空白をあけるという事です。COBOLでは、変数名に、+や-の使用が許可されていますので、スペースがないと、変数の一部なのか、式なのかが判別できないからです。
例)
COMPUTE AAA = BBB - CCC.
BBBからCCCをひいた値を、AAAに入れます。=-の両側には、かならずスペースが必要です。
=のかわりに、ROUNDED = と書くと、結果が四捨五入されます。小数点以下のどこで四捨五入されるかというと、変数1で指定された所の1桁先で四捨五入されます。たとえば、変数1に小数点以下が指定されていないと、小数点以下1位を四捨五入します。
べき乗は、BASICなら^なのですが、COBOLでは**みたいに、アスタリスクを2回書きます。
COMPUTEと他の演算子の違い
COMPUTEを使えば、MOVE、ADD、SUBTRACT、MULTIPLY、DIVIDEはいらないと思う人もいるかもしれませんが、COMPUTEでは、受け側に複数の変数を使う事ができませんし、集団項目を指定する事もできません。
また、COMPUTEではわり算のあまりを直接算出できません。(二段階の計算が必要になる)。さらに、COMPUTEでは四捨五入が指定できます。つまり、MOVE、ADD、SUBTRACT、MULTIPLY、DIVIDE、COMPUTE、は場合によって使い分ける必要があるという事です。
代入
MOVE 変数 1 TO 変数2 変数3 変数4.....
変数1の値を、変数2、変数3、変数4....に代入します。この場合、変数には集団項目を使うことができます。また、表示用変数から計算用変数へ、または、その逆ができます。
加算
ADD 変数1 TO 変数2 変数3 変数4....
変数1の値を、変数2、変数3、変数4...に追加します。変数はすべて計算用として宣言します。
減算
SUBTRACT 変数1 FROM 変数2 変数3 変数4....
変数1の値を、変数2、変数3、変数4...から引きます。変数はすべて計算用として宣言します。
除算
DIVIDE 変数1 BY 変数2 GIVING 変数3 REMAINDER 変数4.
変数1を変数2でわって、商を変数3、あまりを変数4に入れます。変数はすべて計算用として宣言します。変数3に小数点が定義された場合、あまりは、さらにその先の小数点以下になります。
乗算
MULTIPLY 変数1 BY 変数2 GIVING 変数3.
変数1と変数2をかけて、変数3に代入します。変数はすべて計算用として宣言します。
COMPUTE演算子
COMPUTE 変数1 (ROUNDED) = (式).
(式)の結果を、変数1に入れます。変数1は、表示用でも計算用でもかまいませんが、計算用が望ましいようです。コンパイラによっては、変数1が表示用だとバグって変な数になる事があります。
(式)には、+-*/が使えますが、注意して欲しいのは、必ず空白をあけるという事です。COBOLでは、変数名に、+や-の使用が許可されていますので、スペースがないと、変数の一部なのか、式なのかが判別できないからです。
例)
COMPUTE AAA = BBB - CCC.
BBBからCCCをひいた値を、AAAに入れます。=-の両側には、かならずスペースが必要です。
=のかわりに、ROUNDED = と書くと、結果が四捨五入されます。小数点以下のどこで四捨五入されるかというと、変数1で指定された所の1桁先で四捨五入されます。たとえば、変数1に小数点以下が指定されていないと、小数点以下1位を四捨五入します。
べき乗は、BASICなら^なのですが、COBOLでは**みたいに、アスタリスクを2回書きます。
COMPUTEと他の演算子の違い
COMPUTEを使えば、MOVE、ADD、SUBTRACT、MULTIPLY、DIVIDEはいらないと思う人もいるかもしれませんが、COMPUTEでは、受け側に複数の変数を使う事ができませんし、集団項目を指定する事もできません。
また、COMPUTEではわり算のあまりを直接算出できません。(二段階の計算が必要になる)。さらに、COMPUTEでは四捨五入が指定できます。つまり、MOVE、ADD、SUBTRACT、MULTIPLY、DIVIDE、COMPUTE、は場合によって使い分ける必要があるという事です。
サブルーチン
COBOLでは、サブルーチンコールは、ループ制御でも使われるPERFORM命令を使います。
| 例1)1つの節を呼ぶ PERFORM 節. 指定された『節』を呼ぶ。 |
| 例2)指定した段落から段落までを呼ぶ PERFORM 段落1 THRU 段落2. 段落1から段落2までを実行する。 |
例1)の場合、『節』で指定されたSECTIONを呼びます。たとえば、
IN-PROC SECTION.
|
このような『節』が定義されていた場合、PERFORM IN-PORC.と指定すると、IN-PROC SECTIONとされた節を実行します。1つの節は、次の節が現れる手前まで(次の節がない時はソースの終わりまで)を言います。
例2)の場合、指定されたラベルから、指定されたラベルの次のラベルの手前までを実行します。たとえば、
例2)の場合、指定されたラベルから、指定されたラベルの次のラベルの手前までを実行します。たとえば、
SUB-R1.
|
みたいなルーチンがある場合、PERFORM SUB-R1 THRU SUB-R2 とすると、ラベルSUB-R1から、SUB-R3の手前まで実行されます。
ここで注意してほしいのは、SUB-R2のある所までを実行するのではありません。COBOLでは、ラベル~ラベル間を1つの段落とみなしますので、SUB-R2の段落は、次のラベルが表れるまでという意味になるからです。
このように、段落単位でサブルーチンを呼ぶ場合には、サブルーチンの範囲をわかりやすくするために、サブルーチンを終了するための段落を作ります。
ここで注意してほしいのは、SUB-R2のある所までを実行するのではありません。COBOLでは、ラベル~ラベル間を1つの段落とみなしますので、SUB-R2の段落は、次のラベルが表れるまでという意味になるからです。
このように、段落単位でサブルーチンを呼ぶ場合には、サブルーチンの範囲をわかりやすくするために、サブルーチンを終了するための段落を作ります。
| 例) SUB-R1. : : SUB-R1-EN. EXIT. |
みたいに、『段落名-EN』というラベルを作り、『ここが1つのルーチンの終わりですよ』というのを明確にします。ちなみに、EXITは、C言語でいうところの、retuenみたいなものではなく、この命令自体には何の効力もありません。ここがルーチンの終わりだという事を、人間が見てわかるようにするものです。
余談ですが、COBOLには、コンパイラには無視される、人間が見てわかるための命令というのは、けっこうあります。(しかも、変数名としては使えない)。
「節」の方が「段落」よりも上位の分類になります。つまり、節を呼んだ時は途中に段落の境界があっても、そのまま実行を続けます。しかし、段落を呼んだ時は途中に節の区切りがあると、そこで段落は終了します。
ただし、COBOLの慣習では、節の最後にはEXIT.文だけからなる段落を作り、節の先頭には段落名をつける事になっているため、このルールが適用される事はほとんどありません。
余談ですが、COBOLには、コンパイラには無視される、人間が見てわかるための命令というのは、けっこうあります。(しかも、変数名としては使えない)。
「節」の方が「段落」よりも上位の分類になります。つまり、節を呼んだ時は途中に段落の境界があっても、そのまま実行を続けます。しかし、段落を呼んだ時は途中に節の区切りがあると、そこで段落は終了します。
ただし、COBOLの慣習では、節の最後にはEXIT.文だけからなる段落を作り、節の先頭には段落名をつける事になっているため、このルールが適用される事はほとんどありません。
外部サブルーチン
別にコンパイルしたプログラムを呼び出すことができます。
例えば、販売管理システムなら、メニュー、伝票発行、得意先マスタメンテ、得意先リスト、請求書発行などなどを別々にコンパイルしておいて、メニューからユーザーの操作に応じて各プログラムを呼び出す事ができます。
例えば、販売管理システムなら、メニュー、伝票発行、得意先マスタメンテ、得意先リスト、請求書発行などなどを別々にコンパイルしておいて、メニューからユーザーの操作に応じて各プログラムを呼び出す事ができます。
| CALL 外部プログラム名 USING 変数名. |
引数は、呼び出す側は引数となる変数名(集団項目でも良い)をUSINGの後に指定します。呼び出される側では、データー部にLINKAGE SECTION.という節を作り、そこに引数となるメモリーを記述します。Cでいうところのexternみたいな感じ(静的リンクするわけではないので厳密には違いますが)です。
その後、
その後、
| PROCEDURE DIVISION USING 変数名. |
という風に引数となる変数名を指定します。引数の構造は、呼び出し側、呼び出され側ともに同じにしなければなりません。また、USINGを使ってしまうと、(少なくとも、LEVEL
II COBOLでは)単体では動作できなくなります。
LEVEL II COBOLを使っていた当時は、リンケージ部はポインター渡しで、呼び出し側と呼び出され側は同じメモリ領域を示していて、呼び出され側で値を変更すると呼び出し側も変更されました。その後BY REFERENCE(ポインター渡し)、BY CONTENT(参照渡し)、BY VALUE(値渡し)が指定できるようになったようですが、残念ながら私はその方法を知らないので、ここでは取り上げません。
外部サブルーチンはEXIT PROGRAM命令によって終了し、呼び出し側に戻ります。STOP RUNを先に書いてしまうと、呼び出し側には戻らないので注意が必要です。
LEVEL II COBOLを使っていた当時は、リンケージ部はポインター渡しで、呼び出し側と呼び出され側は同じメモリ領域を示していて、呼び出され側で値を変更すると呼び出し側も変更されました。その後BY REFERENCE(ポインター渡し)、BY CONTENT(参照渡し)、BY VALUE(値渡し)が指定できるようになったようですが、残念ながら私はその方法を知らないので、ここでは取り上げません。
外部サブルーチンはEXIT PROGRAM命令によって終了し、呼び出し側に戻ります。STOP RUNを先に書いてしまうと、呼び出し側には戻らないので注意が必要です。
他言語の外部サブルーチン
これは、おそらくMS-DOS版のMicroFocusLEVEL II COBOLやMicroFocusCOBOL/2独自の機能と思われますが、別のコンパイル系言語で作成した外部サブルーチンを呼び出すことができます。例えば、罫線を描画するために直接V-RAMを操作する外部サブルーチンを呼び出す事ができます。
この機能は試験ではまず出ない(と思う)のですが、実際の業務では最も重宝しました。なにしろ、COBOLの命令にない(あっても文法が難しくてよくわからない)機能を、Cやアセンブラで作ってしまう事ができるわけですから。特に文字列操作は、もっぱら外部サブルーチンで行ってました。特に当時のCOBOLでは半角/全角まじりの文字列操作が苦手でしたので。
ただ、罫線を引くためにV-RAMを直接操作するなんて、パソコン・・とりわけMS-DOSの時代でなければまずしないと思います。
以下は罫線サブルーチンを利用している箇所の一部なのですが、WORKING-STORAGE SECTIONに、
この機能は試験ではまず出ない(と思う)のですが、実際の業務では最も重宝しました。なにしろ、COBOLの命令にない(あっても文法が難しくてよくわからない)機能を、Cやアセンブラで作ってしまう事ができるわけですから。特に文字列操作は、もっぱら外部サブルーチンで行ってました。特に当時のCOBOLでは半角/全角まじりの文字列操作が苦手でしたので。
ただ、罫線を引くためにV-RAMを直接操作するなんて、パソコン・・とりわけMS-DOSの時代でなければまずしないと思います。
以下は罫線サブルーチンを利用している箇所の一部なのですが、WORKING-STORAGE SECTIONに、
01 GRAPH-SUB PIC X(11) VALUE "GRAPHIC.BIN".
01 GRAPH-PARAM.
03 GRAPH-FUNC PIC 9(03).
03 GRAPH1 PIC 9(03).
03 GRAPH2 PIC 9(03).
03 GRAPH3 PIC 9(03).
03 GRAPH4 PIC 9(03).
03 GRAPH5 PIC 9(03).
03 GRAPH6 PIC 9(03).
03 GRAPH7 PIC 9(03).
03 GRAPH8 PIC 9(03).
このように定義しておきます。GRAPH-SUBで外部サブルーチンの名前(つまりDOSファイル名)を定義しておきます。また、GRAPH-PARAMで引数のエリアを確保しておきます。ここではUSAGE
DISPLAY形式で定義しています。引数をBINARY指定しておくとアセンブラサブルーチンで扱うのに便利ですが、MicroFocus LEVEL
II COBOL、COBOL/2ではBINARYがビッグエンディアンで格納されるので、8086CPUのアセンブラで処理させるためにリトルエンディアンに変換する必要があります。
実行部であらかじめ引数となるGRAPH-PARAMの各要素に値をMOVE命令でセットしておき、
実行部であらかじめ引数となるGRAPH-PARAMの各要素に値をMOVE命令でセットしておき、
| CALL GRAPH-SUB USING GRAPH-PARAM. |
として外部ルーチンを呼び出します。
呼び出された外部サブルーチンでは、例えばアセンブラなら
_TEXT SEGMENT
ASSUME CS:_TEXT,DS:_TEXT,ES:_TEXT,SS:NOTHING
ORG 100H
の擬似命令を使って、コードセグメント、データーセグメント、エクストラセグメントが同じ、スタックセグメントなしと定義します。Cならタイニーモデルにします。いずれにしても、アセンブル(コンパイル)、リンク後にEXEファイルをEXE2BINでBIN形式にします。
引数がセットされたアドレスは、スタックポインタ+4にセットされてきますので、アセンブラ部で、
呼び出された外部サブルーチンでは、例えばアセンブラなら
_TEXT SEGMENT
ASSUME CS:_TEXT,DS:_TEXT,ES:_TEXT,SS:NOTHING
ORG 100H
の擬似命令を使って、コードセグメント、データーセグメント、エクストラセグメントが同じ、スタックセグメントなしと定義します。Cならタイニーモデルにします。いずれにしても、アセンブル(コンパイル)、リンク後にEXEファイルをEXE2BINでBIN形式にします。
引数がセットされたアドレスは、スタックポインタ+4にセットされてきますので、アセンブラ部で、
PUSH BP
MOV BP,SP
PUSHF
PUSH DS
PUSH ES
PUSH CS
とすると、スタックおよびBPレジスタは下図のようになります。
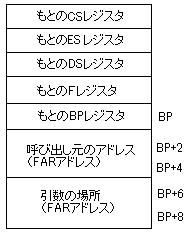
この後、以下のようにDS、ES、SIレジスタをセットします。
この後、以下のようにDS、ES、SIレジスタをセットします。
POP DS
MOV SI,[BP+6]
PUSH [BP+8]
POP ES
DSレジスタをPOPする事で、CSとDSを同一にします。その後、SIレジスタにBP+6・・つまり引数のオフセット値をセットし、ESレジスタにBP+8・・つまり引数のセグメントをセットします。
これで、ES:SIから引数を取り出すことができます。ただし、引数がUSAGE DISPLAYの場合はキャラクターコード(30H~39H)で格納されてくるので、アセンブラの方でバイナリに変換する必要があります。この作業は若干面倒なのですが、COBOLの方で格納形式をBINARYとすると、ビッグエンディアン→リトルエンディアンの変換が必要となり、また、環境の依存性も高くなるので、私は引数をUSAGE DISPLAYとしていました。
アセンブラサブルーチンで一通り処理を終えたところで、最後に
これで、ES:SIから引数を取り出すことができます。ただし、引数がUSAGE DISPLAYの場合はキャラクターコード(30H~39H)で格納されてくるので、アセンブラの方でバイナリに変換する必要があります。この作業は若干面倒なのですが、COBOLの方で格納形式をBINARYとすると、ビッグエンディアン→リトルエンディアンの変換が必要となり、また、環境の依存性も高くなるので、私は引数をUSAGE DISPLAYとしていました。
アセンブラサブルーチンで一通り処理を終えたところで、最後に
POP ES
POP DS
POPF
POP BP
RETF
という風に最初にスタックに退避させておいたES、DS、F、BPレジスタを元に戻して、RETFでFARアドレスにリターンする事で、制御をCOBOLに戻す事ができます。
C言語を使う場合は、スタックの退避などは自動でやってくれますので、引数はmain(char* graph-param)のようにして、charポインタ型の引数として取得すれば良いのですが、9タイプからINT型への変更は必要です。
C言語を使う場合は、スタックの退避などは自動でやってくれますので、引数はmain(char* graph-param)のようにして、charポインタ型の引数として取得すれば良いのですが、9タイプからINT型への変更は必要です。
| コラム キャラクターだけの画面では通用しなくなった時代 80年代後半~90年代前半では、業務システムの画面がキャラクターだけのシンプルなものでも誰も文句は言われなかったのですが、Windows3.1やWindows95が出回るにつれ、もう業務用のソフトであっても画面はカラフルで凝った絵が出るのが当たり前で、実際そういうのでなければ売れませんでした。 90年代後半からMS-DOSから撤退するまでの間は、もうCOBOLで組まれたシステムといいながら、大半は外部サブルーチンコールのプログラムになっていました。8ビット機時代でいうところの、BASIC+機械語、みたいな状態でしょうか。 |
分岐命令
COBOLでは、分岐命令はGO TOを使います。C言語やBASICのような、GOTO ではありません。GO TOです。間にスペースを空けます。(ちなみに、TOは省略可能なコンパイラもある)
| 書式) GO TO 段落名. 段落名で示された所に分岐する。(段落名は、いわゆる『ラベル』のようなもの) |
C言語同様、COBOLでも分岐命令は嫌われ者ですが、C言語ほど『使ってはいけない』とは言われません。それは、C言語のreturn命令みたいな『サブルーチン(関数)から途中で脱出する』という命令がないので、エラー処理、強制終了が必要となった場合など、どうしてもGO TO
で飛ばす必要があるからです。
LEVEL II COBOLでは、PERFORMをループで使えなかったり、END-IFやEVALUTEが使えなかったりしたため、どうしても条件分岐としてIFとGO TOを使わざるをえないという事情もありました。
ただし、サブルーチンの途中から別のサブルーチンやメインルーチンにGO TOしてはいけません。エラーにはなりませんが、スタックがいくつあっても足りなくなります。サブルーチンの途中から脱出する場合は、先に示した、段落名-ENというサブルーチンの終わりの段落へGO TOしましょう。
LEVEL II COBOLでは、PERFORMをループで使えなかったり、END-IFやEVALUTEが使えなかったりしたため、どうしても条件分岐としてIFとGO TOを使わざるをえないという事情もありました。
ただし、サブルーチンの途中から別のサブルーチンやメインルーチンにGO TOしてはいけません。エラーにはなりませんが、スタックがいくつあっても足りなくなります。サブルーチンの途中から脱出する場合は、先に示した、段落名-ENというサブルーチンの終わりの段落へGO TOしましょう。
| 例) KN3. (省略) KN4. DISPLAY "F1:前項目" AT 2259. DISPLAY "西暦和暦差をいれて[ENTER] " AT 2207. ACCEPT 西暦差 AT 1433. IF PFST-2 = 1 GO TO KN3. IF PFST-2 = 10 GO TO PRO-EN. この場合、【F1】キーが押されたら、1つ手前の項目に戻る事ができる。【F10】が押されたら、入力を終了する。 |
キー入力・画面表示
キー入力
COBOL言語には、他の言語には類をみない機能があります。それが、キー入力です。
BASICのINPUTや、LINE INPUT文、C言語のscanf関数など、たいていのコンパイラでは標準で用意された入力命令は、実用になるものではありませんでした。しかし、COBOLの入力命令は使い勝手が良く、単体でも十分実用になるレベルです。これは、きっとCOBOL自体が、ビジネスユース向けに開発された言語だからなのでしょう。
COBOL言語には、他の言語には類をみない機能があります。それが、キー入力です。
BASICのINPUTや、LINE INPUT文、C言語のscanf関数など、たいていのコンパイラでは標準で用意された入力命令は、実用になるものではありませんでした。しかし、COBOLの入力命令は使い勝手が良く、単体でも十分実用になるレベルです。これは、きっとCOBOL自体が、ビジネスユース向けに開発された言語だからなのでしょう。
| 書式) ACCEPT 変数 AT 位置. |
ACCEPT は、キー入力を待つ命令です。(※ソケット待ちではありません) 位置は、ライン/カラムで指定します。たとえば、0302は3ライン目、2カラム目という意味になります。位置には変数を指定する事ができます。9タイプ4桁で指定しますが、大抵はライン/カラムで2桁ずつの集団変数にします。
例)
01 LOC.
03 LOC1 PIC 9(02).
03 LOC2 PIC 9(02).
ここで、LOC1にライン、LOC2にカラムをいれておき、ACCEPT 変数 AT LOC.と書くことで、位置を指定する事ができます。
例)
01 LOC.
03 LOC1 PIC 9(02).
03 LOC2 PIC 9(02).
ここで、LOC1にライン、LOC2にカラムをいれておき、ACCEPT 変数 AT LOC.と書くことで、位置を指定する事ができます。
| 例) LOC1が3、LOC2が2のとき、集団名LOCは、0302となる。よって、AT LOC.と書くと、AT 0302.と書いたのと同じ意味になる。 |
ACCEPTで入力させる変数は、表示用として宣言された変数を使います。
| 例) 01 HENSU1 PIC ----,---,--9. として宣言しておくと、 ACCEPT HENSU1 AT LOC. では、右詰めで3桁ごとにカンマを挿入しながら入力する事ができる。マイナス符号を入力させる事もできる。 |
変数名に、99/99/99と宣言された変数名を使うことで、日付の入力になったり、X(10)と宣言された変数名を使うことで、文字列の入力になったりします。
日付の年は今では4桁を入力させるのが当たり前になっていますが、COBOL全盛期の80年代・90年代では、年を4桁も入力させると必ずクレームになりました。なぜなら、この頃はまだ年を2桁以上入れる習慣がなかったためです。
N(10)は全角入力になりますが、半角英数や半角カタカナまで全部全角に変換してしまうので、通常は使いません。
ACCEPT命令は、Enterキーか、あるいはPFキーが押されたときに終了します。それが、Enterキーで終了したのか、PFキーで終了したのかは、CRT-STATUSで指定した変数に入ります。
ACCEPT命令は、Enterキーか、あるいはPFキーが押されたときに終了します。それが、Enterキーで終了したのか、PFキーで終了したのかは、CRT-STATUSで指定した変数に入ります。
| 例) ENVIRONMENT DIVISION. CONFIGURATION SECTION. (省略) SPECIAL-NAMES. CRT STATUS IS CRT-ST. |
| DATA DIVISION. WORKING-STORAGE SECTION. (省略) 01 CRT-ST. 03 PFST-1 PIC 99 COMP. 03 PFST-2 PIC 99 COMP. 03 PFST-3 PIC 99 COMP. |
のように、環境部で『ACCEPTの終了キーがCRT-STという変数に入りますよ』と宣言しておき、データー部に、CRT-STの本体を宣言します。この場合、PFST-1には、Enterキーが押されたかどうかが入り、PFST-2には、どのPFキーが押されたかが入ります。
| 意味 | 値 | |
|---|---|---|
| PFST-1 | どのキーでACCEPTが終了したか | 48:Enterキー、49:PFキー |
| PFST-2 | どのPFキーが押されたか | PFキー番号(1~10) |
ここで、デフォルトでは[F10]までしか判断できませんが、
MicroFocus Level II COBOLでは、[F11][F12]も判別できるようにカスタマイズする事ができます。
同様に、PFキーだけでなく[Home][End][Esc][↑][↓]などを判別できるようにカスタマイズする事ができます。
ただし、MicroFocus COBOL/2では、そういったカスタマイズができないため、[F1]~[F10]以外に使うことはできないようです。
画面表示
画面表示は、DISPLAY文を使います。
画面表示
画面表示は、DISPLAY文を使います。
| 書式) DISPLAY 変数名 AT 位置. |
変数名や位置は、ACCEPTと同じです。それが入力か出力かの違いだけです。
ACCEPTと同様、ATに続いて座標を指定する事ができます。例えば、
DISPLAY "F1:前項目" AT 2159. DISPLAY "種類コードを指定して[ENTER] " AT 2107. DISPLAY "[F2]一覧 " AT 2207.
とした場合、21ライン59カラム目に、「F1:前項目」と表示され、21ライン7カラム目に「種類コードを指定して[ENTER]」、22ライン7カラム目に「[F2]一覧」と表示されます。
表示位置を変数にしたい場合は、あらかじめ変数を
01 LOC.
03 LOC1 PIC 9(02).
03 LOC2 PIC 9(02).
と定義しておき、LOC1にライン、LOC2にカラムをセットして、 DISPLAY (表示したい内容または変数) AT LOC. と指定します。
この 「AT 位置」で表示位置を指定できる構文はCOBOL85の文法にはなく、MicroFocus系COBOL独自の拡張命令ですが、MicroFocus系と互換性を保っているCOBOLでも使う事ができます。 ちなみにLinuxのopensource-cobolでも使う事ができました。
表示位置を変数にしたい場合は、あらかじめ変数を
01 LOC.
03 LOC1 PIC 9(02).
03 LOC2 PIC 9(02).
と定義しておき、LOC1にライン、LOC2にカラムをセットして、 DISPLAY (表示したい内容または変数) AT LOC. と指定します。
この 「AT 位置」で表示位置を指定できる構文はCOBOL85の文法にはなく、MicroFocus系COBOL独自の拡張命令ですが、MicroFocus系と互換性を保っているCOBOLでも使う事ができます。 ちなみにLinuxのopensource-cobolでも使う事ができました。
コラム CUIで画面設計するには
今でこそGUIで「デザインビュー」なる便利なものがあり、画面のレイアウトの設計はGUI環境でできるようになったために、画面レイアウトの作業がとても楽になりましたが、 MS-DOSのようなCUI環境では、画面デザインをするのは大変でした。
これはコクヨの「ディスプレイレイアウトシート EX64N」という用紙です。(EX64Nはとっくに廃番になっていると思います)
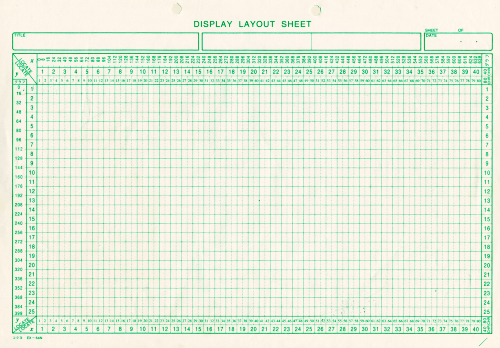
自分も含め、昔の人は皆このようなシートに手書きで、どこに何を表示させるかをまず書き込んでから、それを見ながら手入力で、DISPLAY "・・・・・" AT 位置.というのを 入力(ソースパンチという)するといった、極めてアナログな作業を行っていたわけです。 当然、途中で仕様変更があって表示するものが変わった場合は消しゴムで消して書き直しですし、大幅に変わった場合は1から書き直しでした。
このような作業工程となっているため、自分としては[AT 位置]は必須の機能だったので、知らない人が多かった事には驚きました。知らない人はどうやって画面をレイアウトしていたのでしょう? わざわざカーソル位置を指定するエスケープシーケンスを送っていたのでしょうか?
今でこそGUIで「デザインビュー」なる便利なものがあり、画面のレイアウトの設計はGUI環境でできるようになったために、画面レイアウトの作業がとても楽になりましたが、 MS-DOSのようなCUI環境では、画面デザインをするのは大変でした。
これはコクヨの「ディスプレイレイアウトシート EX64N」という用紙です。(EX64Nはとっくに廃番になっていると思います)
自分も含め、昔の人は皆このようなシートに手書きで、どこに何を表示させるかをまず書き込んでから、それを見ながら手入力で、DISPLAY "・・・・・" AT 位置.というのを 入力(ソースパンチという)するといった、極めてアナログな作業を行っていたわけです。 当然、途中で仕様変更があって表示するものが変わった場合は消しゴムで消して書き直しですし、大幅に変わった場合は1から書き直しでした。
このような作業工程となっているため、自分としては[AT 位置]は必須の機能だったので、知らない人が多かった事には驚きました。知らない人はどうやって画面をレイアウトしていたのでしょう? わざわざカーソル位置を指定するエスケープシーケンスを送っていたのでしょうか?
ファイル入出力
COBOL言語の特徴として、キー入出力の使い勝手の良さがある、と先に述べましたが、ファイルの処理に関する機能が充実しているのもCOBOL言語の特徴の1つです。また、データーがサーバーにある場合を意識した、排他制御を行う事ができます。
ファイルを使うためには、
ファイルを使うためには、
- ファイルの宣言
- バッファの宣言
- オープン・読み書き・クローズの実行
を行う必要があります。
ファイルの宣言
「ファイルの種類」の所で述べたように、SELECT文を使って、内部ファイル名、外部ファイル名、ファイルの種類、キー、ファイルステータスを宣言します。
バッファの宣言
COBOLでは、ファイルごとに読み書きバッファを宣言します。C言語やアセンブラのようなバッファの共有はできません。つまり、1ファイルごとにバッファを別々に固定長で用意しなければならない、という事です。バッファが固定長なので、一度に読み書きする量も固定長になります。
バッファの宣言は、データ部、ファイル節で行います。
ファイルの宣言
「ファイルの種類」の所で述べたように、SELECT文を使って、内部ファイル名、外部ファイル名、ファイルの種類、キー、ファイルステータスを宣言します。
バッファの宣言
COBOLでは、ファイルごとに読み書きバッファを宣言します。C言語やアセンブラのようなバッファの共有はできません。つまり、1ファイルごとにバッファを別々に固定長で用意しなければならない、という事です。バッファが固定長なので、一度に読み書きする量も固定長になります。
バッファの宣言は、データ部、ファイル節で行います。
| 例) FD SHAMAS. 01 SHAREC. 03 SHA1. 05 SHA1-1 PIC 9(05). 05 SHA1-2 PIC 9(05). 03 SHA2 PIC X(20). 03 FILLER PIC X(512). |
FDのあとに、内部ファイル名を書きます。内部ファイル名とは、Perlでいうところのファイルハンドルみたいなものです。FD SHAMASとすると、『このバッファは、SHAMAS用のバッファだ』という意味になります。次に、01とかいて、レコード名を書きます。ファイルをREADする時は内部ファイル名を指定し、ファイルを書くときはレコード名を指定します。
その後に、03や05レベルで、ファイルの詳細を記述します。
なお、先にも述べたように、COBOLのファイルは固定長なので、あとからレコード長を増やす事ができません。(コンバージョンソフトが別途必要になる)。そこで、あとから項目が増えた時に困らないように、予備領域を指定します。これを『FILLERを取っておく』といいます。たとえば、
03 FILLER PIC X(512).
とすると、512バイト予備領域が確保されます。
先に述べた通り、フロッピーにデーターを記録していた頃は、レコード長がちょうどフロッピーのセクタ長になるようにしたものですが、ハードディスクが当たり前になってからは、さほどディスクのセクタ長を意識する必要はなくなりました。(初期の頃のすごい遅いハードディスクを使っていた頃は意識していましたが)
オープン・読み書き・クローズの実行
その後に、03や05レベルで、ファイルの詳細を記述します。
なお、先にも述べたように、COBOLのファイルは固定長なので、あとからレコード長を増やす事ができません。(コンバージョンソフトが別途必要になる)。そこで、あとから項目が増えた時に困らないように、予備領域を指定します。これを『FILLERを取っておく』といいます。たとえば、
03 FILLER PIC X(512).
とすると、512バイト予備領域が確保されます。
先に述べた通り、フロッピーにデーターを記録していた頃は、レコード長がちょうどフロッピーのセクタ長になるようにしたものですが、ハードディスクが当たり前になってからは、さほどディスクのセクタ長を意識する必要はなくなりました。(初期の頃のすごい遅いハードディスクを使っていた頃は意識していましたが)
オープン・読み書き・クローズの実行
| 命令 | 意味 | 書式 |
|---|---|---|
| OPEN | ファイルをオープンする | OPEN モード ファイル名. モード: INPUT 入力 OUTPUT 出力 EXTENDED 追加書き込み I-O 入出力 |
| CLOSE | ファイルを閉じる | CLOSE ファイル名. |
| READ | ファイル読み込み | 1)シーケンシャルファイル READ ファイル名 AT END 終了処理. 2)ランダムファイルと索引ファイル READ ファイル名 KEY IS キー INVALID KEY キーがない場合の処理. 3)索引ファイルの順読み READ ファイル名 NEXT AT END 終了処理. |
| START | ファイルの読み込みポインタの設定 | START ファイル名 KEY IS NOT LESS THAN キー INVALID KEY キーがない場合の処理. |
| WRITE | レコードの書き込み | WRITE レコード名 INVALID KEY 書き込みできない場合の処理. |
| REWRITE | レコードの更新 | REWRITE レコード名 INVALID KEY 更新できない場合の処理. |
| DELETE | レコードの削除 | DELETE ファイル名. |
| UNLOCK | ロックの解除 | UNLOCK ファイル名. |
OPEN
ファイルをオープンします。
INPUTはファイルの読み込みを行います。ファイルが存在しないとエラーになります。(OPTIONALが指定されていない場合)。
OUTPUTは、ファイルを書き出します。すでにファイルが存在していた場合はファイルサイズをゼロにしてしまいます。
EXTENDEDは、ファイルを追加書き込みします。既にファイルが存在している場合、そのファイルに追加されます。
I-Oは、ファイルの読み込みと書き込みの両方を行います。ランダムアクセスする場合に使います。ファイルが存在しないと、ファイルサイズゼロのものが作成されます。
例)
OPEN INPUT KANMAS.
KANMASというファイルを読み込み用にオープンします。
OPEN INPUT KANMAS WITH LOCK.
KANMASというファイルを読み込み専用にオープンし、ファイルをロックします。
OPEN I-O TOKMAS.
TOKMASというファイルを、読み書き両用モードでオープンします。
READ
ファイルを読み込みます。シーケンシャルファイルと、ランダムファイル、それに索引ファイルでは、それぞれ使い方が異なります。
シーケンシャルファイルの場合、
READ KANMAS AT END GO TO 中止.
KANMASというファイルを読み込み、すでに最後まで読み込んでいてこれ以上読めない場合は、中止というルーチンに行きます。
ランダムファイル・索引ファイルをランダム読みする場合、
READ TOKMAS KEY IS TK1 INVALID KEY PERFORM TOKBUFF-C.
TOKMASというファイルを、TK1をキーにして読み込み、もし読めなければTOKBUFF-Cというルーチンを呼ぶ。
ランダムファイル・索引ファイルを順読みする場合、
READ TOKMAS NEXT AT END GO TO TOK-OWAIRI.
TOKMASというファイルを、事前にSTART文で指定された場所から読み込み、すでに終了していたらTOK-OWARIというルーチンに行く。
ランダムファイルと索引ファイルは、それぞれ『ランダム読み』『順読み』ができます。『ランダム読み』は、必要なレコード1件だけ読み込みます。たとえば、TK1が得意先コードだったとして、
MOVE 1 TO TK1.
として、得意先コードに1を入れておいて、READ TOKMAS INVALID KEY ....と書くことで、得意先コード1のデーターを取り出す事ができます。
キーは数字だけでなく、文字列も使うことができます。たとえば、J31GT021Aという商品コードをキーに設定しておいて、指定の商品コードをもつ商品の詳細情報をファイルから引き出すという事ができます。
『順読み』は、キーを若い順に読み出します。つまり、得意先一覧表などを作成する場合に、得意先コードの若い順にレコードを取り出したい時に使います。
また、排他制御を行う事ができます。たとえば、READ TOKMAS WHTH LOCK と書くと、読み出したレコードをロックして、他の端末から読めなくします。
START
ファイルの読み込みポインタを設定します。
START 内部ファイル名 KEY IS NOT LESS THAN キー INVALID KEY ...
ファイルポインタを、キーに指定された所に設定します。ちなみに、NOT LESS THANは、「少なくない」「同じか大きい」という意味です。たとえば、得意先コード5番以降のデーターが欲しい時は、MOVE 5 TO TK1.とした後、KEY IS NOT LESS THAN TK1 とします。
指定されたキーより少なくない(=同じか大きい)データーがない場合は、INVALID KEYのあとに記述した文を実行します。
WRITE
ファイルを書き込みます。
WRITE TOKREC INVALID KEY …
この場合、内部ファイル名ではなくレコード名を記述する事に注意してください。レコード名とは、そのファイルバッファの01レベルの集団名の事をいいます。キーが重複してる等の理由で書き込みができない場合は、INVALID KEYの後に書いた文が実行されます。SQLに例えるとinsertみたいなものです。
REWRITE
ファイルを更新します。
REWRITE TOKREC INVALID KEY …
たとえば、得意先コード1番のレコードが既に存在している場合、WRITE命令で1番のレコードを書こうとすると、INVALIDになって書けませんので、REWRITE命令をいます。同じ主キーが存在しない場合はINVALID KEYの後の文が実行されます。SQLでいうところのupdateみたいなものですが、更新する条件として主キーが必要です。あらかじめ主キーに値をセットしておきます。
ファイルをオープンします。
INPUTはファイルの読み込みを行います。ファイルが存在しないとエラーになります。(OPTIONALが指定されていない場合)。
OUTPUTは、ファイルを書き出します。すでにファイルが存在していた場合はファイルサイズをゼロにしてしまいます。
EXTENDEDは、ファイルを追加書き込みします。既にファイルが存在している場合、そのファイルに追加されます。
I-Oは、ファイルの読み込みと書き込みの両方を行います。ランダムアクセスする場合に使います。ファイルが存在しないと、ファイルサイズゼロのものが作成されます。
例)
OPEN INPUT KANMAS.
KANMASというファイルを読み込み用にオープンします。
OPEN INPUT KANMAS WITH LOCK.
KANMASというファイルを読み込み専用にオープンし、ファイルをロックします。
OPEN I-O TOKMAS.
TOKMASというファイルを、読み書き両用モードでオープンします。
READ
ファイルを読み込みます。シーケンシャルファイルと、ランダムファイル、それに索引ファイルでは、それぞれ使い方が異なります。
シーケンシャルファイルの場合、
READ KANMAS AT END GO TO 中止.
KANMASというファイルを読み込み、すでに最後まで読み込んでいてこれ以上読めない場合は、中止というルーチンに行きます。
ランダムファイル・索引ファイルをランダム読みする場合、
READ TOKMAS KEY IS TK1 INVALID KEY PERFORM TOKBUFF-C.
TOKMASというファイルを、TK1をキーにして読み込み、もし読めなければTOKBUFF-Cというルーチンを呼ぶ。
ランダムファイル・索引ファイルを順読みする場合、
READ TOKMAS NEXT AT END GO TO TOK-OWAIRI.
TOKMASというファイルを、事前にSTART文で指定された場所から読み込み、すでに終了していたらTOK-OWARIというルーチンに行く。
ランダムファイルと索引ファイルは、それぞれ『ランダム読み』『順読み』ができます。『ランダム読み』は、必要なレコード1件だけ読み込みます。たとえば、TK1が得意先コードだったとして、
MOVE 1 TO TK1.
として、得意先コードに1を入れておいて、READ TOKMAS INVALID KEY ....と書くことで、得意先コード1のデーターを取り出す事ができます。
キーは数字だけでなく、文字列も使うことができます。たとえば、J31GT021Aという商品コードをキーに設定しておいて、指定の商品コードをもつ商品の詳細情報をファイルから引き出すという事ができます。
『順読み』は、キーを若い順に読み出します。つまり、得意先一覧表などを作成する場合に、得意先コードの若い順にレコードを取り出したい時に使います。
また、排他制御を行う事ができます。たとえば、READ TOKMAS WHTH LOCK と書くと、読み出したレコードをロックして、他の端末から読めなくします。
START
ファイルの読み込みポインタを設定します。
START 内部ファイル名 KEY IS NOT LESS THAN キー INVALID KEY ...
ファイルポインタを、キーに指定された所に設定します。ちなみに、NOT LESS THANは、「少なくない」「同じか大きい」という意味です。たとえば、得意先コード5番以降のデーターが欲しい時は、MOVE 5 TO TK1.とした後、KEY IS NOT LESS THAN TK1 とします。
指定されたキーより少なくない(=同じか大きい)データーがない場合は、INVALID KEYのあとに記述した文を実行します。
WRITE
ファイルを書き込みます。
WRITE TOKREC INVALID KEY …
この場合、内部ファイル名ではなくレコード名を記述する事に注意してください。レコード名とは、そのファイルバッファの01レベルの集団名の事をいいます。キーが重複してる等の理由で書き込みができない場合は、INVALID KEYの後に書いた文が実行されます。SQLに例えるとinsertみたいなものです。
REWRITE
ファイルを更新します。
REWRITE TOKREC INVALID KEY …
たとえば、得意先コード1番のレコードが既に存在している場合、WRITE命令で1番のレコードを書こうとすると、INVALIDになって書けませんので、REWRITE命令をいます。同じ主キーが存在しない場合はINVALID KEYの後の文が実行されます。SQLでいうところのupdateみたいなものですが、更新する条件として主キーが必要です。あらかじめ主キーに値をセットしておきます。
| 例) WRITE TOKREC INVALID KEY REWRITE TOKREC. 得意先のレコードを書き込みしますが、キーがすでに存在したら更新します。 |
DELETE
レコードを削除します。SQLのdeleteみたいなものですが、条件として主キーが必要です。あらかじめ主キーに値をセットしておきます。例えば、得意先番号10番の会社が倒産するか、取引停止などで削除したい場合、MOVE 10 TO TK1.とした後に、DELETE TOKMAS.というふうにします。
DELETE命令ではファイルそのものを削除する事ができないため、ファイルそのものをハードディスクから削除するためには、別途アセンブラやCで外部サブルーチンを作っておいて、それを呼び出す必要があります。ただし、ファイルサイズを0にするのであれば、出力専用でOPENしてすぐCLOSEするという方法もあります。
COBOLの索引ファイルは、SQLのようなリレーショナルデーターベースではなくポインター型なので、レコードが大量にある時に、その中の1件を削除しようとすると、ポインターをすべて更新するため、凄い時間がかかってしまいます。このため、『条件にあったレコードすべて削除』する場合、DELETEするのではなく、『残すファイルを別ファイルで退避させておき、リネームする』方が良いです。私の体験では、ファイルをDELETE命令で連続して消すようになっているソフトが終了するまで、5時間以上待たされた事がありますしたが、『残すファイルを退避してリネームする』方式に直したところ、数分で終了したという事がありました。ただし、この方法はあくまでMS-DOSなどのシングルタスクのOSでの動作が前提となります。
UNLOCK
ファイルのロックと、レコードロックを解除します。ファイルの更新などでロックをかける場合、終わったらただちにロックを解除してください。さもないと、他の端末で、同じファイルを更新しようとして延々と待たされている可能性があります。
UNLOCK TOKMAS.
とすると、TOKMAS のファイルロックおよびレコードロックをすべて解除します。
また、COBOLではPostgreSQLのようなデッドロック検知機能は基本的にはないので、デッドロックしないように、複数ファイルをロックする場合に、ロックさせる順番には最大限の注意を払います。
CLOSE
ファイルを閉じます。同時に、ファイルロックやレコードロックも解除します。遅延キャッシュにたまっていた索引ファイルを更新します。
索引ファイルのWRITEやREWTITEやDELETEを行った場合、ただちにファイルをCLOSEして、再度OPENしてください。索引ファイルのWRITEやREWRITEやDELETEは、COBOLの方である程度遅延キャッシュにためて、CLOSEする時にまとめて書き込むのですが、そのせいで書き込み後にCLOSEしないでプログラムが中断した場合(停電、電源オフ、エラー、[Ctrl]+[C]キー)、索引ファイルが壊れ、次から読み書きができなくなってしまいます。
フロッピーディスクにデーターを記録していた時代では索引ファイルの遅延キャッシュも役に立っていたのですが、ハードディスクが普及するにつれ、遅延キャッシュがファイル破損のリスクを増やすだけという結果になってしまいました。
ファイルステータス
ファイルが壊れていた場合には、エラーメッセージを出してプログラムが強制終了します。また、ファイルがロックされていた場合は、ロックが解除されるまで延々と待ちます。『それじゃ困る』という場合、ファイルステータスを設定します。
レコードを削除します。SQLのdeleteみたいなものですが、条件として主キーが必要です。あらかじめ主キーに値をセットしておきます。例えば、得意先番号10番の会社が倒産するか、取引停止などで削除したい場合、MOVE 10 TO TK1.とした後に、DELETE TOKMAS.というふうにします。
DELETE命令ではファイルそのものを削除する事ができないため、ファイルそのものをハードディスクから削除するためには、別途アセンブラやCで外部サブルーチンを作っておいて、それを呼び出す必要があります。ただし、ファイルサイズを0にするのであれば、出力専用でOPENしてすぐCLOSEするという方法もあります。
COBOLの索引ファイルは、SQLのようなリレーショナルデーターベースではなくポインター型なので、レコードが大量にある時に、その中の1件を削除しようとすると、ポインターをすべて更新するため、凄い時間がかかってしまいます。このため、『条件にあったレコードすべて削除』する場合、DELETEするのではなく、『残すファイルを別ファイルで退避させておき、リネームする』方が良いです。私の体験では、ファイルをDELETE命令で連続して消すようになっているソフトが終了するまで、5時間以上待たされた事がありますしたが、『残すファイルを退避してリネームする』方式に直したところ、数分で終了したという事がありました。ただし、この方法はあくまでMS-DOSなどのシングルタスクのOSでの動作が前提となります。
UNLOCK
ファイルのロックと、レコードロックを解除します。ファイルの更新などでロックをかける場合、終わったらただちにロックを解除してください。さもないと、他の端末で、同じファイルを更新しようとして延々と待たされている可能性があります。
UNLOCK TOKMAS.
とすると、TOKMAS のファイルロックおよびレコードロックをすべて解除します。
また、COBOLではPostgreSQLのようなデッドロック検知機能は基本的にはないので、デッドロックしないように、複数ファイルをロックする場合に、ロックさせる順番には最大限の注意を払います。
CLOSE
ファイルを閉じます。同時に、ファイルロックやレコードロックも解除します。遅延キャッシュにたまっていた索引ファイルを更新します。
索引ファイルのWRITEやREWTITEやDELETEを行った場合、ただちにファイルをCLOSEして、再度OPENしてください。索引ファイルのWRITEやREWRITEやDELETEは、COBOLの方である程度遅延キャッシュにためて、CLOSEする時にまとめて書き込むのですが、そのせいで書き込み後にCLOSEしないでプログラムが中断した場合(停電、電源オフ、エラー、[Ctrl]+[C]キー)、索引ファイルが壊れ、次から読み書きができなくなってしまいます。
フロッピーディスクにデーターを記録していた時代では索引ファイルの遅延キャッシュも役に立っていたのですが、ハードディスクが普及するにつれ、遅延キャッシュがファイル破損のリスクを増やすだけという結果になってしまいました。
ファイルステータス
ファイルが壊れていた場合には、エラーメッセージを出してプログラムが強制終了します。また、ファイルがロックされていた場合は、ロックが解除されるまで延々と待ちます。『それじゃ困る』という場合、ファイルステータスを設定します。
| 例) SELECT KANMAS ASSIGN TO "KANMAS.DAT" ORGANIZATION SEQUENTIAL FILE STATUS IS FILE-ST. (略) |
| 01 FILE-ST. 03 FST1 PIC 9. 03 FST2 PIC 99 COMP. |
KANMASというファイルの情報を、FILE-STという変数に格納する。この場合、エラーが発生してもプログラムは中断しません。エラー処理ルーチンを自分で作る事ができます。
| FST1 | 0:正常終了。 1:ファイルが存在しない。 2:キーが重複している。 9:ファイルが壊れている。 |
| FST2 | 68:ファイルがロックされている。 69:レコードがロックされている。 |
FST1が「9」の場合、ただちにプログラムを終了し、ファイルの修復処理等を行います。また、「2」の場合、旧レコードを削除するか更新するかの処理を行います。「1」の場合、さしつかえなければ、読み込みバッファを初期化するだけで次の命令に進みます。
FST2は、ファイルやレコードが他の端末でロックされているかどうかの情報が入ります。ロックされていた場合、規定回数リトライを行って他の端末がロックを解除するのを待つか、メッセージを表示してファイルの処理ができない事をユーザーに知らせます。PERFORMを使い、有限ループでロックが解除されるまで待つルーチンを自前で作る事で、デッドロックを防止する事ができます。
ご注意
ファイルのロックといった排他制御は、東芝から発売されていたJ-3100用のMicroFocus LEVEL II COBOLでは実装されていませんでした。なので、他のLEVEL II COBOLでも使えないかもしれません。
マニュアルにはちゃんと排他制御についての記載があったので、当時東芝に問い合わせたところ、「マニュアルは誤解を招いてしまって申し訳ありません」という返答がありましたが、その時既にLANで複数ユーザーがファイルにアクセスする仕事を受注してしまった後だったので焦りました。
FST2は、ファイルやレコードが他の端末でロックされているかどうかの情報が入ります。ロックされていた場合、規定回数リトライを行って他の端末がロックを解除するのを待つか、メッセージを表示してファイルの処理ができない事をユーザーに知らせます。PERFORMを使い、有限ループでロックが解除されるまで待つルーチンを自前で作る事で、デッドロックを防止する事ができます。
ご注意
ファイルのロックといった排他制御は、東芝から発売されていたJ-3100用のMicroFocus LEVEL II COBOLでは実装されていませんでした。なので、他のLEVEL II COBOLでも使えないかもしれません。
マニュアルにはちゃんと排他制御についての記載があったので、当時東芝に問い合わせたところ、「マニュアルは誤解を招いてしまって申し訳ありません」という返答がありましたが、その時既にLANで複数ユーザーがファイルにアクセスする仕事を受注してしまった後だったので焦りました。
その他の命令
以下に挙げる命令は、試験には頻繁に出題されるそうなのですが、実践ではほとんど使わないのであまり詳しい説明はしません。しかしながら、古いシステムを移行するためにはある程度意味がわかっていた方が良いと思い、簡単に説明しておきます。
SORTとMERGE
SORTやMERGEは、シーケンシャルファイルをソートする命令です。SORTは1つのファイルを、MERGEは複数のファイルを連結して、ソートした結果をファイルに出力します。
しかし、実際にはあまり実用的ではないので使いませんでした。なぜ実用的ではないのかといいますと、ソート中に一切の進捗表示はなく、また、中止キーなどの割り込みをかける事ができなかったのです。なので、今ソートが何パーセント終わっていて、あと何分(何時間?)かかるかわからないものを、延々とユーザーに待たせるわけにはいかなかったのでした。
私はSORT命令のかわりに、ISAMの一時ファイルを使っていました。これはSORT命令よりも処理時間はかかりますが、進捗を表示でき、途中で中止もできるという点で体感的な待ち時間は段違いでしょう。
文字列操作
COBOLの変数は固定長ですので、PerlやPHPのように文字列を途中で区切ったり連結したりするのは苦手なのですが、それでも文字列操作の命令は用意されていました。 しかし、当時のCOBOLはマルチバイトに対応しておらず、文字列操作命令を使うと全角文字の1バイト目と2バイト目で切れちゃったりして、残念ながら日本のようなマルチバイトの言語を使う国では役に立ちませんでした。
文字列操作関数はマルチバイトに対応していないだけでなく、命令文が非常に長いので、それを覚えるぐらいなら別途アセンブラで外部サブルーチンを作った方がてっとり早かったのでした。このページのアクセスログ(Googleから検索で来ているログ)を調べると、全角半角まじりの文字列を連結したり、分割したりする方法を調べたい人が多いようですが、私は結局COBOLでは実現できず、アセンブラ外部サブルーチンで「文字列操作ライブラリ」を作って実現していました。
・INSPECT
『文字列の特定の文字を置き換える』『文字列の、特定の文字の出現回数を数える』事ができます。PHPでいうところの、str_replaceやsubstr_count、また、Perlでいうところの、s///;みたいなものです。
・STRING/UNSTRING
STRINGは文字列の連結を、UNSTRINGは文字列の分解を行います。UNSTRINGは、Perlのsplit、PHPのexplodeみたいなものです。
その他
SYNCHRONIZED 、RELEASE、RETURN、SEARCH という命令があり、 試験には頻繁に出題されるようですが、私は使いませんでした。
SORTとMERGE
SORTやMERGEは、シーケンシャルファイルをソートする命令です。SORTは1つのファイルを、MERGEは複数のファイルを連結して、ソートした結果をファイルに出力します。
しかし、実際にはあまり実用的ではないので使いませんでした。なぜ実用的ではないのかといいますと、ソート中に一切の進捗表示はなく、また、中止キーなどの割り込みをかける事ができなかったのです。なので、今ソートが何パーセント終わっていて、あと何分(何時間?)かかるかわからないものを、延々とユーザーに待たせるわけにはいかなかったのでした。
私はSORT命令のかわりに、ISAMの一時ファイルを使っていました。これはSORT命令よりも処理時間はかかりますが、進捗を表示でき、途中で中止もできるという点で体感的な待ち時間は段違いでしょう。
文字列操作
COBOLの変数は固定長ですので、PerlやPHPのように文字列を途中で区切ったり連結したりするのは苦手なのですが、それでも文字列操作の命令は用意されていました。 しかし、当時のCOBOLはマルチバイトに対応しておらず、文字列操作命令を使うと全角文字の1バイト目と2バイト目で切れちゃったりして、残念ながら日本のようなマルチバイトの言語を使う国では役に立ちませんでした。
文字列操作関数はマルチバイトに対応していないだけでなく、命令文が非常に長いので、それを覚えるぐらいなら別途アセンブラで外部サブルーチンを作った方がてっとり早かったのでした。このページのアクセスログ(Googleから検索で来ているログ)を調べると、全角半角まじりの文字列を連結したり、分割したりする方法を調べたい人が多いようですが、私は結局COBOLでは実現できず、アセンブラ外部サブルーチンで「文字列操作ライブラリ」を作って実現していました。
・INSPECT
『文字列の特定の文字を置き換える』『文字列の、特定の文字の出現回数を数える』事ができます。PHPでいうところの、str_replaceやsubstr_count、また、Perlでいうところの、s///;みたいなものです。
・STRING/UNSTRING
STRINGは文字列の連結を、UNSTRINGは文字列の分解を行います。UNSTRINGは、Perlのsplit、PHPのexplodeみたいなものです。
その他
SYNCHRONIZED 、RELEASE、RETURN、SEARCH という命令があり、 試験には頻繁に出題されるようですが、私は使いませんでした。
プログラム終了
プログラムを終了させるために、STOP RUN.という命令を入れます。この命令に出会うと、
プログラムは終了し、プロンプトに戻ります。
また、EXIT
PROGRAM.という命令があります。これは、CALL命令にて呼ばれた親プロセスに戻るという意味です。
STOP RUN.や、EXIT、EXIT PROGRAM.いずれの場合も、 COBOLでは「その命令だけからなる段落を作成する」という習慣になっていますので、それに従います。
メニューからCALL命令で呼び出されたプログラムがSTOP RUNに出会うと、 元のメニューではなくプロンプト(つまりC:\>)に戻ってしまうので、 メニューから呼ばれるプログラムは、STOP RUNの前にEXIT PROGRAMを入れる必要があります。 もちろん、プロンプトに戻るというのはMS-DOS版の話です。
STOP RUN.や、EXIT、EXIT PROGRAM.いずれの場合も、 COBOLでは「その命令だけからなる段落を作成する」という習慣になっていますので、それに従います。
メニューからCALL命令で呼び出されたプログラムがSTOP RUNに出会うと、 元のメニューではなくプロンプト(つまりC:\>)に戻ってしまうので、 メニューから呼ばれるプログラムは、STOP RUNの前にEXIT PROGRAMを入れる必要があります。 もちろん、プロンプトに戻るというのはMS-DOS版の話です。
例)
PRO-EN1.
EXIT PROGRAM.
PRO-EN2.
STOP RUN.
おわりに
COBOL言語はファイルの操作機能や、桁数の多い数値の計算、入出力機能が充実している反面、
V-RAMなどハードに近い部分の制御には非常に弱いものです。
COBOLを実践で使うには、COBOLの弱点であるハードに近い部分をアセンブラやC言語で作ったサブプログラムに任せて、 得意のファイル操作の部分をCOBOLで記述するのが、もっともバランスの良い使い方だと思います。
COBOLを実践で使うには、COBOLの弱点であるハードに近い部分をアセンブラやC言語で作ったサブプログラムに任せて、 得意のファイル操作の部分をCOBOLで記述するのが、もっともバランスの良い使い方だと思います。
 このページの先頭へ
このページの先頭へ
広告