8086アセンブラ入門
「アセンブラ」と「コンパイラ」
アセンブラ言語とコンパイラ言語は、一見同じようなものに見えます。実際に、『プログラムを作る』という目的は同じです。しかし、中身はまったく違います。コンパイラは、その文法を解釈し機械語コードを生成するのに対し、アセンブラは単純に命令を16進数に変換するだけです。(もちろん、それは『基本的には』であり、実際には疑似命令やラベルなどの処理は行いますが)。例えば、
| PUSH BP MOV BP,SP PUSHF |
→ → → |
55 8B EC 9C |
みたいに変換します。
コンピューターが理解できる言葉は、この『55 8B EC 9C』という数値(16進数)だけです。コンピューターは、この16進数を命令として受け取り、プログラムを実行するわけです。8ビットコンピューターの頃は、この16進数(機械語ともいう)を、直接人間がコード表(ニーモニック)を見ながら打ち込んだり(ハンドアセンブル)したものですが、さすがにデバッグ効率も悪く、作るだけでも大変な手間になってしまいます。
そこで、この『55』を『PUSH BP』とか、『9C』を『PUSHF』という風に、人間が少しでもわかる言葉に直したものが、アセンブラ言語です。コンパイラとアセンブラの決定的な違いはここにあります。
コンピューターが理解できる言葉は、この『55 8B EC 9C』という数値(16進数)だけです。コンピューターは、この16進数を命令として受け取り、プログラムを実行するわけです。8ビットコンピューターの頃は、この16進数(機械語ともいう)を、直接人間がコード表(ニーモニック)を見ながら打ち込んだり(ハンドアセンブル)したものですが、さすがにデバッグ効率も悪く、作るだけでも大変な手間になってしまいます。
そこで、この『55』を『PUSH BP』とか、『9C』を『PUSHF』という風に、人間が少しでもわかる言葉に直したものが、アセンブラ言語です。コンパイラとアセンブラの決定的な違いはここにあります。
| コンパイラ | アセンブラ | |
|---|---|---|
| 人間が入力するもの | 文法に定められた言語、ラベル、ポイントタ | 16進数つけられた名前(ニーモニック) ラベル、アドレス |
| 機械語(16進数)への変換 | 文法を解釈して生成する | 16進数につけられた名前をそのまま変換する |
アドレス
アセンブラを学習する上で避けて通れないのが「アドレス」と「レジスタ」です。特に、アドレスという概念はアセンブラ以外ではほとんど意識する事はないでしょう。(C言語では、ポインタという形で若干意識する必要はありますが。)アドレスとは、簡単にいえば、メモリに割り付けられた住所の事です。
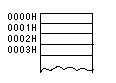 |
図のように、メモリには住所(アドレス)がつけられていて、メモリのデーターを読み書きする際にはこのアドレスを指定するようになっています。たとえば、0000H番地にFFHを書き込むきに、MOV
[0000H],BYTE PTR 0FFHという風にします。 ※『H』は、『16進数』を示します。 |
セグメント
8086系のCPUでは、メモリを「セグメント」という形で分割して扱います。
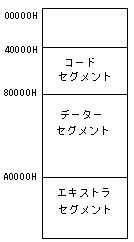 |
たとえば、図のように4000Hをコードセグメント、8000Hをデーターセグメント、A000Hをエキストラセグメントに設定します。すると、コードセグメント上の1番地(CS:00001Hと表記する)は、
|
このように、8086CPUでは、00000H~0FFFFFHまでの、1MBの空間を、それぞれ「セグメント」とよばれる64KBのエリアに分割しながら扱えるように設計されています。ちなみに、これは16ビットCPU主流の頃の話であり、今では32ビット(やそれ以上)のCPUである、80386、486、ペンティアム、ペンティアムII……等が使われているのですが、MS-DOSのような16ビットCPU用に設計されたOSでは、32ビットCPUを「仮想86モード」という、8086として動作するモードで動かします。
ここでは8086CPUを使う、もしくは、仮想86モードを使うものとして話をすすめていきましょう。
プログラムで、メモリにアクセスする場合、『MOV AX,DS:[0001H]』みたいに記述します。しかし、単なるMOVE命令では省略すると自動的にデーターセグメントを使う事になっているため、データーセグメントにアクセスする時は、『MOV AX,[0001H]』と、『DS:』を省略して書きます。(省略した際に使われるセグメントは、命令によって異なります。)
ここでは8086CPUを使う、もしくは、仮想86モードを使うものとして話をすすめていきましょう。
プログラムで、メモリにアクセスする場合、『MOV AX,DS:[0001H]』みたいに記述します。しかし、単なるMOVE命令では省略すると自動的にデーターセグメントを使う事になっているため、データーセグメントにアクセスする時は、『MOV AX,[0001H]』と、『DS:』を省略して書きます。(省略した際に使われるセグメントは、命令によって異なります。)
レジスタ
レジスターというと、お店にある会計をする機械の事を思い浮かべる人が多いと思います。しかし、ここではレジスタとはCPUがメモリを読み書きするために使うものをいいます。レジスタは、一部(C言語)で使う以外、コンパイラ言語ではほとんど出てきません。しかし、アセンブラではレジスタを使わずにプログラムを作る事はできません。ここでは、そのレジスタの働きを説明します。
CPUがメモリを書き換える際に使うのが、レジスタです。レジスタとは簡単にいうと『数値を一時的にとっておくための手』と思ってください。たとえば、人間が物を移動させる場合、通常は『手』に物を持ち、それを移動先に置きます。これと同じようなことをCPUが行うわけです。
CPUがメモリを書き換える際に使うのが、レジスタです。レジスタとは簡単にいうと『数値を一時的にとっておくための手』と思ってください。たとえば、人間が物を移動させる場合、通常は『手』に物を持ち、それを移動先に置きます。これと同じようなことをCPUが行うわけです。
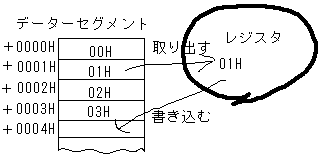 |
たとえば、データーセグメント内の、00001H番地の内容を、00004H番地内に移動させる場合を考えます。MOVSBという命令もあるのですが、ここでは説明のためにあえてMOV命令で記述すると、 MOV AL,[00001H] MOV [00004H],AL となります。これは、「ALレジスタに1番地の内容を入れろ」「4番地にALレジスタの内容を書け」という意味になります。 |
8086CPUでは、レジスタは以下のものがあります。
| レジスタ | 長さ | 用途 | レジスタ | 長さ | 用途 | ||
|---|---|---|---|---|---|---|---|
| AX | AH | 8ビット | 16ビット | 計算。メモリの書き換え。 | CS | 16ビット | コードセグメントを示す。 |
| AL | 8ビット | DS | 16ビット | データーセグメントを示す。 | |||
| BX | BH | 8ビット | 16ビット | 計算。ソースインデックスのベースアドレス。 | ES | 16ビット | エキストラセグメントを示す。 |
| BL | 8ビット | SS | 16ビット | スタックセグメントを示す。 | |||
| CX | CH | 8ビット | 16ビット | カウンター。 | F | 16ビット | フラグ |
| CL | 8ビット | IP | 16ビット | 今実行中のプログラムの場所 | |||
| DX | DH | 8ビット | 16ビット | AXレジスタと組み合わせた32ビット長の計算。 | |||
| DL | 8ビット | ||||||
| SI | 16ビット | ソースインデックス。(アドレス格納) | |||||
| DI | 16ビット | ディスティネーションインデックス。(アドレス格納) | |||||
| BP | 16ビット | ポインタのベースアドレス。 | |||||
| SP | 16ビット | スタックポインタ | |||||
モトローラ系の68000系などは、レジスタごとに役割が決まってない(それぞれ汎用で使える)のですが、8086CPUではレジスタごとに役割分担がはっきりしているようです。もちろん、上記用途以外でも使えないことはないのですが、SIのオフセット値としてBXレジスタやBPレジスタは使えて、AXレジスタはつかえないとか、ループやシフト命令を使う時にはCXレジスタが使われるなど、用途別に使い分けた方がなにかと都合が良いように設計されています。
ラベル
これまでの説明では、アドレスは直接番地を指定してきましたが、実際には番地を直接書くのはまれで、「ラベル」というものを使います。たとえば、
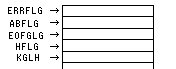 |
ERRFLG ABFLG EOFFLG HFLG KFLG |
DB 0 DB 0 DB 0 DB 0 DB 0 |
このように、メモリに名前を付けます。実際にどの番地に割り当てられるかは、コンパイル時に決まります。(どのセグメントにロードされるかは、プログラムがメモリにロードされた時に決まります。)以後は、メモリの書き換えはアドレスを意識する事なく、このラベルを使って指定する事ができます。
| 例) MOV AL,[ERRFLG] |
表記
8086系のアセンブラでは、表記にいくつかの決まりごとがあります。中には他の言語と大きく異なる点もあります。
大文字小文字
アセンブラでは(特に指定しない限り、デフォルトでは)大文字と小文字は区別しません。つまり、label_1とLABEL_1は同じ意味になります。また、ニーモニックの記述は大文字でも小文字でもかまいません。なので、全て大文字で記述する人もいれば、全て小文字で記述する人などまちまちです。
私のような8ビットマシンのBASIC+アセンブラからこの世界に入った人は、アセンブラの記述も全て大文字で書いてしまうのですが、最初にC系の言語(C、C++、PHP、Perl)から入った人は小文字で記述する人が多いようです。
16進数
16進数を表記するためには、うしろにHをつけます。10Hは、10進数では16になります。
ただし先頭にA~Fまでの文字が来る場合、ラベルなのか16進数なのか区別ができなくなるため、16進数である事を明記するために、先頭に0(ゼロ)を補います。たとえば、FFHだけだとラベルなのか16進数なのか区別がつかないため、16進数なら0FFHとします。(ちなみに、0がないとFFHというラベルとして扱われます。)
2進数
アセンブラでは、フラグを操作する時など、よく2進数を扱います。2進数は後ろにBをつけます。たとえば、00100Bは、10進数で4になります。
10進数
10進数は、そのまま表記すれば10進数になります。しかし、10進数である事を明確にする時は、うしろにDをつけます。
アドレス
アドレス参照なのか、即値なのかを区別するために、[](カギカッコ)を使います。たとえば、MOV AX,1とすると、AXレジスタに「1」が入り、MOV AX,[1]とすると、メモリの1番地に書いてある内容がAXレジスタに入ります。
バイト・ワード
8086アセンブラでは、1バイトを「バイト」、2バイトを「ワード」と呼びます。AXレジスタなど、16ビット単位で数値を扱う場合は「ワード単位で扱う」と呼びます。
大文字小文字
アセンブラでは(特に指定しない限り、デフォルトでは)大文字と小文字は区別しません。つまり、label_1とLABEL_1は同じ意味になります。また、ニーモニックの記述は大文字でも小文字でもかまいません。なので、全て大文字で記述する人もいれば、全て小文字で記述する人などまちまちです。
私のような8ビットマシンのBASIC+アセンブラからこの世界に入った人は、アセンブラの記述も全て大文字で書いてしまうのですが、最初にC系の言語(C、C++、PHP、Perl)から入った人は小文字で記述する人が多いようです。
16進数
16進数を表記するためには、うしろにHをつけます。10Hは、10進数では16になります。
ただし先頭にA~Fまでの文字が来る場合、ラベルなのか16進数なのか区別ができなくなるため、16進数である事を明記するために、先頭に0(ゼロ)を補います。たとえば、FFHだけだとラベルなのか16進数なのか区別がつかないため、16進数なら0FFHとします。(ちなみに、0がないとFFHというラベルとして扱われます。)
2進数
アセンブラでは、フラグを操作する時など、よく2進数を扱います。2進数は後ろにBをつけます。たとえば、00100Bは、10進数で4になります。
10進数
10進数は、そのまま表記すれば10進数になります。しかし、10進数である事を明確にする時は、うしろにDをつけます。
アドレス
アドレス参照なのか、即値なのかを区別するために、[](カギカッコ)を使います。たとえば、MOV AX,1とすると、AXレジスタに「1」が入り、MOV AX,[1]とすると、メモリの1番地に書いてある内容がAXレジスタに入ります。
バイト・ワード
8086アセンブラでは、1バイトを「バイト」、2バイトを「ワード」と呼びます。AXレジスタなど、16ビット単位で数値を扱う場合は「ワード単位で扱う」と呼びます。
転送
メモリからレジスタに数値を入れたり、メモリにレジスタの中身を書き出したりする場合に、MOVを使います。
| MOV レジスタ,メモリ | メモリ→レジスタに転送します。 |
| MOV メモリ,レジスタ | レジスタ→メモリに転送します。 |
| MOV レジスタ1,レジスタ2 | レジスタ2→レジスタ1に転送します。 |
| MOV メモリ,即値 | メモリに即値を転送します。 |
転送の方向は、COBOLとは違い、右から左になることに注意してください。(MOV AX,1は、「1」→「AX」と転送される)。レジスタに16ビット長のレジスタを指定した場合、自動的にメモリは16ビット単位(ワード)で転送されます。ただし、即値をメモリに入れる時は、バイト単位なのかワード単位なのかわかりません。そこで、コンパイラに、バイトかワードかをかを指示します。これは、「BYTE
PTR」および「WORD PTR」と表記します。
| 例) MOV [AFLG],BYTE PTR 1 メモリ[AFLG]に、「1」を、バイト単位で転送する。 |
演算
演算命令には、ADD、SUB、MUL、DIVなどがあります。
| 命令 | 書式 | 意味 |
|---|---|---|
| ADD | ADD レジスタ,即値 | レジスタに即値の値を足します。 |
| ADD メモリ,即値 | メモリに即値の値を足します。(WORD PTR かBYTE PTRの指定が必要) | |
| ADD レジスタ1,レジスタ2 | レジスタ1とレジスタ2を足して、レジスタ1に入れます。 | |
| ADC | ADDと同じように機能しますが、さらにキャリーフラグの値も足します。 | |
| SUB | SUB レジスタ,即値 | レジスタから、即値の値を引きます。 |
| SUB メモリ,即値 | メモリから即値の値を引きます。(WORD PTR かBYTE PTRの指定が必要) | |
| SUB レジスタ1,レジスタ2 | レジスタ1からレジスタ2を引いて、結果をレジスタ1に入れます。 | |
| SBB | SUBと同じように機能しますが、さらにキャリーフラグも引きます。 | |
| MUL | MUL 8ビットレジスタ | 指定レジスタとALレジスタをかけて、結果をAXレジスタに入れる。 |
| MUL 16ビットレジスタ | 指定レジスタとAXレジスタをかけて、結果をDX:AXレジスタに入れる。 | |
| MUL BYTE PTR メモリ | 指定メモリの値とALレジスタをかけて、結果をAXレジスタに入れる。 | |
| MUL WORD PTR メモリ | 指定メモリの値とAXレジスタをかけて、結果をDX:AXレジスタに入れる。 | |
| IMUL | MULを符号付きで行う。 | |
| DIV | DIV 8ビットレジスタ | AXレジスタから指定レジスタを割って、商をALあまりをAHレジスタに入れる。 |
| DIV 16ビットレジスタ | DX:AXレジスタから指定レジスタを割って、商をAXあまりをDXレジスタに入れる。 | |
| DIV BYTE PTR メモリ | AXレジスタから指定メモリを割って、商をALあまりをAHレジスタに入れる。 | |
| DIV WORD PTR メモリ | DX:AXレジスタから指定メモリを割って、商をAXあまりをDXレジスタに入れる。 | |
| IDIV | DIVを符号付きで行う。 | |
ここで注意するのは、『わり算』です。ゼロで割ったり、商がALレジスタ(あるいはAXレジスタ)に収まりきれない場合は、INT 0が発生します。MS-DOSでは「0で除算しました」というエラーメッセージを発してプログラムを終了します。DOSプロンプトの時は、『このプログラムは不正な処理を行ったので強制終了します』と出ます。
コンパイラやインタプリタ言語では、大抵の場合CPUが0で割るような事がないように事前にチェックをし、Division by zeroなどのエラーを出力するようになっていますが、アセンブラで0で割ってしまうともうプログラムでエラー処理をかます事ができなくなるため、通常は割る前に0で除算してないかどうか、また、商がオーバーフローしないかどうかをチェックする必要があります。
もし、16ビット以上の足し算をしたい場合はどうすればいいのでしょう。その場合、ADCを使います。まず下位バイト同士を足した後、ADC命令を使って上位バイト同士を足します。すると、下位バイトで発生した桁上がり(キャリーフラグ)が足されるため、32ビット(やそれ以上)の足し算が可能になります。
コンパイラやインタプリタ言語では、大抵の場合CPUが0で割るような事がないように事前にチェックをし、Division by zeroなどのエラーを出力するようになっていますが、アセンブラで0で割ってしまうともうプログラムでエラー処理をかます事ができなくなるため、通常は割る前に0で除算してないかどうか、また、商がオーバーフローしないかどうかをチェックする必要があります。
もし、16ビット以上の足し算をしたい場合はどうすればいいのでしょう。その場合、ADCを使います。まず下位バイト同士を足した後、ADC命令を使って上位バイト同士を足します。すると、下位バイトで発生した桁上がり(キャリーフラグ)が足されるため、32ビット(やそれ以上)の足し算が可能になります。
ビットシフト演算
10進数で1を1桁あげると10となり10倍になります。8進数で001を1桁繰り上げると010(=8)となり8倍になります。のように、n進数では、1桁くりあげるとn倍になります。なので、2進数では1桁くりあげると2倍になります。ビットシフト演算は、レジスタまたはメモリのビットをシフトして、二進数の桁のくり上げや、くり下げなどを行います。
たとえば、二進数00000001を1つ左にシフトしてみます。
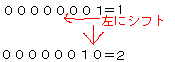
のように、結果は『2』になり、『2倍』になりました。
左シフトを繰り返すと、2、4、8、16、32、64、128、256、という風に、どんどん2倍になってゆきます。このように、単純に2倍、もしくは1/2倍にしたい場合、時間のかかるMULやDIVを用いることなく、ビットシフト命令で代用できます。
たとえば、二進数00000001を1つ左にシフトしてみます。
のように、結果は『2』になり、『2倍』になりました。
左シフトを繰り返すと、2、4、8、16、32、64、128、256、という風に、どんどん2倍になってゆきます。このように、単純に2倍、もしくは1/2倍にしたい場合、時間のかかるMULやDIVを用いることなく、ビットシフト命令で代用できます。
| 左シフト | 右シフト | 意味 | 図 | 使用例 |
|---|---|---|---|---|
| SHL | SHR | ビットをシフトし、はみ出た分はキャリーフラグにセットされる。 | 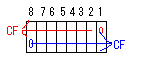 |
SHL AX,1 AXレジスタを左に1回シフトする。 SHR AX,CL AXレジスタを右に、CLレジスタ分だけシフトする。 ※シフト量は、1または、CLが指定できる。 |
| SAL | SAR | ビットをシフトし、はみ出た分はキャリーフラグにセットされる。 右シフトの時は最上位ビットは保存され、2番目のビットにコピーされる。 |
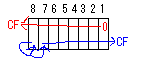 |
|
| ROL | ROR | ビットをシフトし、はみ出た分は、最上位(または最下位)ビットに移動する。 |  |
|
| RCL | RCR | ビットをキャリーフラグを含んでシフトする。 | 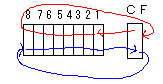 |
ここで、もし、DX:AXレジスタを左シフトしたい場合は、SHL
AX,1でAXレジスタを左シフトした後、RCL DX,1でキャリーフラグを含んでシフトします。
論理演算
論理演算は、主にビットを操作する時に使います。
AND
両方のビットが1のとき、1、どちらかが0の時0になります。つまり、特定のビットだけを調べたい時に使います。
AND
両方のビットが1のとき、1、どちらかが0の時0になります。つまり、特定のビットだけを調べたい時に使います。
例)
最上位ビット以外は必ず0になるため、他のビットに関係なく最上位ビットが0かどうかを調べることができる。 |
OR
どちらかのビットが1なら1になります。特定のビットを1にする時に使います。
どちらかのビットが1なら1になります。特定のビットを1にする時に使います。
例)
最上位ビットは必ず1になるため、他のビットをそのままにして、最上位ビットを1にしたいときに使う。 |
XOR
両方のビットが同じなら0、異なっていたら1になります。
両方のビットが同じなら0、異なっていたら1になります。
例)
両方のビットが全部同じなため、0になります。自分自身とXORを取ることで、0にする事ができます。 |
NOT
ビットを反転させます。
ビットを反転させます。
例)
ビットが反転され、1が0に、0が1になります。 |
NEG
符号を反転させます。具体的には、ビットを反転させた後、+1します。
符号を反転させます。具体的には、ビットを反転させた後、+1します。
例)
1の符号を反転させ、-1(つまり、FF)にします。 |
論理演算は主にI/Oポートを操作する時などで、特定のビットをたてたり、おろしたりする時に使います。
分岐
構造化プログラミングでは、分岐命令はとかく嫌われ者ですが、アセンブラでは分岐命令なしにプログラムを組むのは不可能です。とくに、条件判断はすべて分岐命令ですので、分岐命令なしでは条件判断すらできない事になります。
JMP
指定されたアドレスに分岐します。分岐には相対分岐と絶対分岐があります。とはいえ、6809のように命令が違うわけではなく、両方ともJMP命令を使います。ただ、オペランドにレジスタやメモリが指定されたときは絶対分岐、即値が指定された時は相対分岐になります。
JMP
指定されたアドレスに分岐します。分岐には相対分岐と絶対分岐があります。とはいえ、6809のように命令が違うわけではなく、両方ともJMP命令を使います。ただ、オペランドにレジスタやメモリが指定されたときは絶対分岐、即値が指定された時は相対分岐になります。
| JMP 即値 | 即値(もしくはラベル)で示された場所に相対分岐する。 |
| JMP レジスタ | レジスタのアドレスに絶対分岐する。 |
| JMP WORD PTR[メモリ] | メモリで示された場所に書いてあるアドレスに分岐する。 |
| JMP DWORD PTR[メモリ] | メモリで示された場所(オフセット:セグメント)に分岐する。 |
相対分岐とは、「今そのプログラムが実行されている場所から、どれだけ離れたところに分岐するか」という値で分岐します。アセンブラでは、分岐先のラベルを指定する事で、自動的に計算してくれるので、その辺を気にする必要はないです。
ここで、1バイトで表現できる場所への分岐(-128~+127バイト以内)なら、分岐先を1バイトで表します。また、2バイトで表現できる場所への分岐は、分岐先を2バイトで表します。
ただし、分岐先が、今そのプログラムが実行されている場所(IP)より後ろで、+127バイト以内の分岐だった場合、NOPが挿入され、命令全体が3バイトにそろえられます。なぜならば、今のアドレスより手前のアドレスは既にアドレスが確定されているから良いのですが、今のアドレスより後ろのアドレスは、今実行中の命令(この場合JMP)の長さが変わると、アドレスも当然かわってしまうので、計算ができなくなってしまうからです。
このことは、次の条件分岐を使う場合に影響します。
条件分岐
フラグの状態により分岐します。
ここで、1バイトで表現できる場所への分岐(-128~+127バイト以内)なら、分岐先を1バイトで表します。また、2バイトで表現できる場所への分岐は、分岐先を2バイトで表します。
ただし、分岐先が、今そのプログラムが実行されている場所(IP)より後ろで、+127バイト以内の分岐だった場合、NOPが挿入され、命令全体が3バイトにそろえられます。なぜならば、今のアドレスより手前のアドレスは既にアドレスが確定されているから良いのですが、今のアドレスより後ろのアドレスは、今実行中の命令(この場合JMP)の長さが変わると、アドレスも当然かわってしまうので、計算ができなくなってしまうからです。
このことは、次の条件分岐を使う場合に影響します。
条件分岐
フラグの状態により分岐します。
| 符号なし | 符号付き | 意味 |
|---|---|---|
| JA、JNBE | JG、JNLE | 大きい、同じか小さくない |
| JAE、JNB | JGE、JNL | 同じか大きい、小さくない |
| JE、JZ | JE、JZ | 同じ、ゼロ |
| JBE、JNA | JLE、JNG | 同じか小さい、大きくない |
| JB、JNAE | JL、JNGE | 小さい、同じか大きくない |
| JNE、JNZ | JNE、JNZ | 同じじゃない、ゼロじゃない |
分岐命令は同じ命令にも2通りの書き方がありますが、生成されるコードは同じです。
条件分岐命令に続いて分岐先をアドレス(ラベル)で指定します。条件が成立していれば、指定のアドレス(ラベル)に分岐します。(条件が成立しなければ、何もせず符号なしの条件判断では、上(Above)、下(Below)の頭文字を取って、「JA」とか「JB」とかいう表現が使われます。
うち消す場合は、NotのNを用いて、「JNA」とか「JNB」とか書きます。『または同じ』という場合は、同じ(Equal)のEをとって、JAEとか、JBEとか書きます。符号付きの場合は、大きい(Great)と小さい(Low)の頭文字をとって、JGとか、JLとかいう風に書きます。符号なしの場合、『大きい』か『小さい』かの判断はキャリーフラグを使います。直前の命令、SUBもしくはCMPを使って、キャリーフラグを変化させます。
条件分岐命令に続いて分岐先をアドレス(ラベル)で指定します。条件が成立していれば、指定のアドレス(ラベル)に分岐します。(条件が成立しなければ、何もせず符号なしの条件判断では、上(Above)、下(Below)の頭文字を取って、「JA」とか「JB」とかいう表現が使われます。
うち消す場合は、NotのNを用いて、「JNA」とか「JNB」とか書きます。『または同じ』という場合は、同じ(Equal)のEをとって、JAEとか、JBEとか書きます。符号付きの場合は、大きい(Great)と小さい(Low)の頭文字をとって、JGとか、JLとかいう風に書きます。符号なしの場合、『大きい』か『小さい』かの判断はキャリーフラグを使います。直前の命令、SUBもしくはCMPを使って、キャリーフラグを変化させます。
| 例) CMP AX,1 JA HANDAN1 AXと1を比較して、大きければHANDAN1へ分岐する。 |
この場合、CMPとは『非破壊検査』といって、AXレジスタから1を引いたものとして(実際には引かない)、AXの方が小さければキャリーフラグをセットします。また、AXと1が同じならば、ゼロフラグをセットします。同様に、符号ありの場合、サインフラグとオーバーフローフラグを使って判断します。
ここで問題なのは『条件分岐には、ショートジャンプしかない』という点です。6809のような、LBRAとかLBSRみたいにロング分岐命令なんてものはありませんし、JSRみたいに絶対分岐命令もありません。じゃあ、飛び先が-128~+127だった場合どうするか、という問題にぶつかります。この場合、
解決法1:ジャンプテーブルを作る
ここで問題なのは『条件分岐には、ショートジャンプしかない』という点です。6809のような、LBRAとかLBSRみたいにロング分岐命令なんてものはありませんし、JSRみたいに絶対分岐命令もありません。じゃあ、飛び先が-128~+127だった場合どうするか、という問題にぶつかります。この場合、
解決法1:ジャンプテーブルを作る
| 例) CMP AX,1 JB TBL1 JMP TBL2 TBL1: JMP 飛び先A TBL2: JMP 飛び先B |
+127バイト以内に、『飛び先へ飛ぶための飛び先』があって、そこへ条件分岐させる方法です。この方法は思いつきやすい反面、ややこしいのが欠点です。なにしろ、飛び先のラベルの他に、飛び先へいくためのラベルまで必要になります。
解決法2:判断を逆転させる
解決法2:判断を逆転させる
| CMP AX,1 JA $+5 JMP TBL1 |
つまり、「大きければ分岐」は、「同じか小さければ分岐しない」という風に、また「同じならば分岐」は「違えば分岐しない」という風に、考え方を逆転させて考えます。この場合、「同じか小さければ分岐」したいので、「大きければ分岐命令を飛ばす」というふうに書きます。この方法もかなりややこしいのですが、ジャンプテーブル方式よりもリストがすっきりします。
ただし、注意してください。$+5は、『今実行中の命令よりも5バイト後』という意味ですが、それに続くJMP命令が、そこのアドレスよりも手前への分岐だった場合、JMP命令が2バイトになってしまう事があるからです。
この場合、次の命令の飛び先の距離によって$+4にしたり、$+5にしたりするのでは、微妙な距離の場合に困ってしまうので、次の分岐命令はできるだけ下のアドレスへの分岐に統一します。やむをえず手前に分岐するときは、とりあえず$+5としておき、次に必ずNOPを1つ入れるという手もありますが、素直にラベルを記述した方が良いでしょう。
ただし、注意してください。$+5は、『今実行中の命令よりも5バイト後』という意味ですが、それに続くJMP命令が、そこのアドレスよりも手前への分岐だった場合、JMP命令が2バイトになってしまう事があるからです。
この場合、次の命令の飛び先の距離によって$+4にしたり、$+5にしたりするのでは、微妙な距離の場合に困ってしまうので、次の分岐命令はできるだけ下のアドレスへの分岐に統一します。やむをえず手前に分岐するときは、とりあえず$+5としておき、次に必ずNOPを1つ入れるという手もありますが、素直にラベルを記述した方が良いでしょう。
IN、OUT
IN、OUTは、I/Oポートを読み書きする命令です。これができる事が、アセンブラプログラムの最大の利点といえます。
C言語でも多少はできるますが、やはりI/Oポートを直接制御するような部分には、インラインアセンブルなどでアセンブラ言語で記述してある事が多いようです。I/Oポートとは、コンピューターに接続(または内蔵)された機器に対して情報をやりとりするための『窓口』だと思ってください。
C言語でも多少はできるますが、やはりI/Oポートを直接制御するような部分には、インラインアセンブルなどでアセンブラ言語で記述してある事が多いようです。I/Oポートとは、コンピューターに接続(または内蔵)された機器に対して情報をやりとりするための『窓口』だと思ってください。
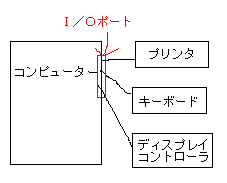 |
コンピューターと機器はこのようにI/Oポートを通して情報をやりとりします。(ちなみに、ポートは『港』の意味です) 実際に、どのポートを、どう操作すれば、どの機械が制御できるかは、パソコンによって決まっています。互換性を持たせるためには、I/Oポートの場所や制御方法は同じにしておく必要があります。(したがって、AT互換機同士は、I/Oポートは互換性があります) |
たとえば、ディスプレイコントローラーに「プレーン2のV-RAMの情報を用意しろ」という命令(厳密にはちょっと違うが)を送るには、
MOV AL,02H
MOV DX,3C4H
OUT DX,AL
MOV AL,2
MOV DX,3C5H
OUT DX,AL
みたいにして、03C4H、03C5Hという2つのI/Oポートに数値を出力します。同様に、V-RAMのオフセットレジスタの値を読むためには、IN命令を用いて
MOV AL,13H
MOV DX,03D4H
OUT DX,AL
MOV DX,03D5H
IN AL,DX
みたいにして書きます。
どのI/Oポートを、どう操作すれば、何がおこるかは、その目的のパソコンの詳細資料が必要になります。つまり、アセンブラでプログラムを作るためには、アセンブラの記述方法を知っている事はもちろん、目的のパソコンの資料をできる限り集めなくてはならないという事になります。アセンブラでグラフィックスの描写ルーチンを作っていた頃の私の部屋は、J-3100やPC-9801、AT互換機の資料でいっぱいでした。
また、I/Oポートを操作する場合、同じ互換機同士、たとえばPC/AT互換機同士でもCPU速度によってウェイトのタイミングがうまくいかなかったり、その機種独自のクセのようなものがあったりして、互換性を損ねてしまう(いわゆる『相性の関係で動かないというやつ』)ので、できる限り避けます。
私も、I/Oポートを操作するのは、どうしても速度を上げたい場合(つまり、画面制御でV-RAMを直接書き換えるプログラム)にとどめています。プリンターの制御など、さほど処理速度を要求しない場合はBIOSを使うようにします。
MOV AL,02H
MOV DX,3C4H
OUT DX,AL
MOV AL,2
MOV DX,3C5H
OUT DX,AL
みたいにして、03C4H、03C5Hという2つのI/Oポートに数値を出力します。同様に、V-RAMのオフセットレジスタの値を読むためには、IN命令を用いて
MOV AL,13H
MOV DX,03D4H
OUT DX,AL
MOV DX,03D5H
IN AL,DX
みたいにして書きます。
どのI/Oポートを、どう操作すれば、何がおこるかは、その目的のパソコンの詳細資料が必要になります。つまり、アセンブラでプログラムを作るためには、アセンブラの記述方法を知っている事はもちろん、目的のパソコンの資料をできる限り集めなくてはならないという事になります。アセンブラでグラフィックスの描写ルーチンを作っていた頃の私の部屋は、J-3100やPC-9801、AT互換機の資料でいっぱいでした。
また、I/Oポートを操作する場合、同じ互換機同士、たとえばPC/AT互換機同士でもCPU速度によってウェイトのタイミングがうまくいかなかったり、その機種独自のクセのようなものがあったりして、互換性を損ねてしまう(いわゆる『相性の関係で動かないというやつ』)ので、できる限り避けます。
私も、I/Oポートを操作するのは、どうしても速度を上げたい場合(つまり、画面制御でV-RAMを直接書き換えるプログラム)にとどめています。プリンターの制御など、さほど処理速度を要求しない場合はBIOSを使うようにします。
ソフトウェア割り込み
ソフトウェア割り込みに関する命令は、以下のような種類があります。
| 命令 | 意味 |
|---|---|
| INT 割り込み番号 | 割り込み番号で示した割り込み処理へ分岐する。 |
| IRET | 割り込み処理から抜ける。 |
| STI | 割り込み処理を許可する。 |
| CLI | 割り込み処理を禁止する。 |
INTは主にBIOSやDOS割り込みを呼び出すために使います。
| 例)プリンターに、スペース量補正コマンドを送る MOV AH,0 MOV AL,1CH MOV DX,0 INT 17H MOV AH,0 MOV AL,55H MOV DX,0 INT 17H |
この場合、INT 17Hという「プリンターBIOS」を呼びしました。また、
| 例)ファイルをリードモードでオープンする MOV AH,3DH MOV AL,00010010B MOV DX,OFFSET SFILE INT 21H |
この場合、ファイルをオープンするという、MS-DOS割り込みを呼びました。
MS-DOS割り込みとは、INT 21Hを使った割り込みの事で、MS-DOSが用意した『基本プログラム』です。これは、MS-DOS搭載マシン全体で互換性があります。(もっとも、バージョンによって違いはありますが)。したがって、MS-DOS割り込みだけを使ってプログラムを作れば、「MS-DOS互換」というプログラムが作れる事になります。
BIOSとは、そのパソコンに用意された『基本プログラム』です。たとえば、プリンターに1バイト出力したり、キーボードから1文字入力したりという、汎用的なプログラムは、あらかじめ機械の方で用意されています。これを使うことにより、機械同士のクセやウェイトのタイミングなどの『相性の問題』を吸収してくれます。
これらの基本プログラムは、ソフトウェア割り込みを使って呼び出します。どのソフトウェア割り込みをつかうと、何が起こるかは、MS-DOS割り込みやBIOS割り込みに関する情報を記した資料が必要になります。I/Oポートの制御と同様、資料を集める必要があります。
とにかく、アセンブラ使いは、資料を集めなくてはいけないという事です。アセンブラでプログラムを作る場合にしても、互換性のためになるべく以下のようにします。
MS-DOS割り込みとは、INT 21Hを使った割り込みの事で、MS-DOSが用意した『基本プログラム』です。これは、MS-DOS搭載マシン全体で互換性があります。(もっとも、バージョンによって違いはありますが)。したがって、MS-DOS割り込みだけを使ってプログラムを作れば、「MS-DOS互換」というプログラムが作れる事になります。
BIOSとは、そのパソコンに用意された『基本プログラム』です。たとえば、プリンターに1バイト出力したり、キーボードから1文字入力したりという、汎用的なプログラムは、あらかじめ機械の方で用意されています。これを使うことにより、機械同士のクセやウェイトのタイミングなどの『相性の問題』を吸収してくれます。
これらの基本プログラムは、ソフトウェア割り込みを使って呼び出します。どのソフトウェア割り込みをつかうと、何が起こるかは、MS-DOS割り込みやBIOS割り込みに関する情報を記した資料が必要になります。I/Oポートの制御と同様、資料を集める必要があります。
とにかく、アセンブラ使いは、資料を集めなくてはいけないという事です。アセンブラでプログラムを作る場合にしても、互換性のためになるべく以下のようにします。
- なるべくMS-DOS割り込みだけで作る
- MS-DOS割り込みだけでできない部分だけは、BIOSを使う。
- DOS割り込みでもBIOSでもできない場合、I/Oポートを「しかたなく」操作する。
サブルーチンとスタック
頻繁に使うルーチンを『サブルーチン』にして、メインルーチンから呼びます。サブルーチンを呼ぶためには、CALLを使います。
| CALL ラベル | ラベルの場所にサブルーチンコールする。 |
| CALL [ラベル] | ラベルの場所に書いてあるアドレスにサブルーチンコールする。 |
| CALL DWORD PTR [ラベル] | ラベルの書いてあるアドレス(オフセット:セグメント)にサブルーチンコールする。 |
| RET | サブルーチンから戻る(NEARアドレス) |
| RETF | サブルーチンから戻る(FARアドレス) |
CALL命令がくると、プログラムはサブルーチンに制御を移します。具体的には、サブルーチンから戻る番地をスタックに保存した後、サブルーチンへ制御がうつる(IPがサブルーチンのアドレスにセットされる)わけです。
また、RETがくると、サブルーチンから復帰します。具体的には、スタックのアドレスをIPに戻し、スタックをポップします。ここで、スタックとは、「データーを一時的に保存しておく場所」という事です。
また、RETがくると、サブルーチンから復帰します。具体的には、スタックのアドレスをIPに戻し、スタックをポップします。ここで、スタックとは、「データーを一時的に保存しておく場所」という事です。
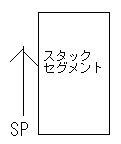 |
スタックは、スタックセグメント内に確保され、上のアドレスからどんどん下のアドレスに向かって使用されます。 スタックは、最後に入れた値から順に取り出されます。(ラストIN・ファーストOUT)。 |
スタックの用途は、レジスタの保存や、CALL時の戻り番地の保存に使われます。また、C言語ではローカル変数の保存に使ったり、関数通しのパラメーターの受け渡しにも使います。(Cだけでなく、COBOLでも、アセンブラルーチンへのパラメーターの受け渡しに使われます)
スタックにデーターを入れることを「PUSHする」といいます。また、スタックからデーターを取り出す事を「POPする」といいます。スタックは、最後にPUSHしたものが、POPすると出てきます。つまり、
PUSH BP
PUSHF
PUSH AX
PUSH BX
としてレジスタを保存した場合、取り出す時は
POP BX
POP AX
POPF
POP BP
という風に、PUSHした時とは逆順にPOPしなければなりません。(この順番をわざと変えて、レジスタの内容を交換するという事もできます)
レジスタにPUSHしたデーターは、必ずPOPしなければなりません。でないと、そのプログラムが1回実行するたびにスタックポインタが手前に下がってしまい、しまいには重要なデーターを壊す(スタックアウトする)場合があるからです。また、PUSH、POPの数が合ってないと、サブルーチンからも復帰できなくなります。
しかし、どうしてもスタックを一気に破棄したいという場合は、ADD SP,+2のように、スタックポインタを増やしてしまうという方法もあります。この場合、そのルーチンを通る時点でスタックがどれぐらい詰まれているかを正しく把握する必要があります。条件によってスタックのつまれる量が違ったりすると思わぬバグの元になります。
スタックにデーターを入れることを「PUSHする」といいます。また、スタックからデーターを取り出す事を「POPする」といいます。スタックは、最後にPUSHしたものが、POPすると出てきます。つまり、
PUSH BP
PUSHF
PUSH AX
PUSH BX
としてレジスタを保存した場合、取り出す時は
POP BX
POP AX
POPF
POP BP
という風に、PUSHした時とは逆順にPOPしなければなりません。(この順番をわざと変えて、レジスタの内容を交換するという事もできます)
レジスタにPUSHしたデーターは、必ずPOPしなければなりません。でないと、そのプログラムが1回実行するたびにスタックポインタが手前に下がってしまい、しまいには重要なデーターを壊す(スタックアウトする)場合があるからです。また、PUSH、POPの数が合ってないと、サブルーチンからも復帰できなくなります。
しかし、どうしてもスタックを一気に破棄したいという場合は、ADD SP,+2のように、スタックポインタを増やしてしまうという方法もあります。この場合、そのルーチンを通る時点でスタックがどれぐらい詰まれているかを正しく把握する必要があります。条件によってスタックのつまれる量が違ったりすると思わぬバグの元になります。
ストリング命令
ストリング命令は、単純な命令を繰り返し実行する事ができます。また、LOOP命令を使ってループを作るよりも実行速度ははるかに高速になります。V-RAMを同じ値で一気に塗りつぶす時とか、別の場所にコピーする場合とかに有効です。
STOS
ALレジスタか、AXレジスタの内容を、DS:[SI]で示すアドレスに書き出します。
STOS
ALレジスタか、AXレジスタの内容を、DS:[SI]で示すアドレスに書き出します。
| STOSB | ALレジスタをES:[DI]に書き出す。 |
| STOSW | AXレジスタをES:[DI]に書き出す。 |
これをリピート命令と組み合わせて使うことによって、連続したアドレスに対して行う事ができます。
| 例) MOV AX,0 MOV CX,10 CLD REP STOSW AXレジスタの内容(ここでは0)を、ES:[DI]で示すアドレスに書いて、DIレジスタを+2する。これを、CXで示した数(10回)実行する。 |
ここで、CXレジスタは繰り返す回数を指定します。ES:[DI]レジスタは1回実行するたびに+2します。なお、CLDのかわりにSTDが指定さえた場合、1回実行するごとに、DIレジスタを-2します。(アドレスの若い方に向かって繰り返します)。
MOVS
DS:[SI]レジスタで示したアドレスから、ES:[DI]レジスタで示したアドレスへ、メモリを転送する。
MOVS
DS:[SI]レジスタで示したアドレスから、ES:[DI]レジスタで示したアドレスへ、メモリを転送する。
| MOVSB | DS:[SI]レジスタで示したアドレスから、ES:[DI]レジスタで示したアドレスへ、メモリを転送する。転送は1バイトごとに行われる。 |
| MOVSW | DS:[SI]レジスタで示したアドレスから、ES:[DI]レジスタで示したアドレスへ、メモリを転送する。転送は2バイトごとに行われる。 |
ここで、MOVSWは2バイト単位で転送が行われるので、MOVSBより高速になります。なお、MOVSBではALレジスタが、MOBSWではAXレジスタが転送の際に使用され、最後に転送した値がAX(AL)レジスタに残ります。
SCAS
ALレジスタ(もしくは、AXレジスタ)の値と、ES:[DI]レジスタで示された場所の値を比較します。これは、REPEもしくは、REPNE命令と共に使います。
SCAS
ALレジスタ(もしくは、AXレジスタ)の値と、ES:[DI]レジスタで示された場所の値を比較します。これは、REPEもしくは、REPNE命令と共に使います。
| 例) MOV AX,0 MOV CX,10 CLD REPNE SCASW AXレジスタの値(ここでは0)と、ES:[DI]の値と比較する。同じものがあるまで、CXレジスタの数(10回)まで繰り返す。 |
CMPS
DS:[SI]とES:[DI]の値を比較します。
DS:[SI]とES:[DI]の値を比較します。
| 例) MOV CX,10 CLD REPNE CMPSW DS:[SI]と、ES:[DI]の値と比較する。同じものがあるまで、CXレジスタの数(10回)まで繰り返す。 |
SCAS、CMPSともに、1バイト単位なら、SCASB、CMPSB、2バイト単位ならSCASW、CMPSWと書きます。また、REPEと書くと「同じ限り繰り返す」となり、REPNEと書くと「違う限り繰り返す」という意味になります。
その他
あまり使わない命令ですが、知っておくと何かと便利な命令です。
LEA
アドレスをレジスタにセットします。たとえば、LEA BX,[SI]と書くと、SIレジスタの示すアドレスにある値ではなく、SIレジスタの値そのものがBXレジスタに入ります。また、LEA DI,[SI+BX]と書くと、DIレジスタには、SI+BXの結果そのものが入ります。
LDS
DSレジスタと、指定レジスタに値を同時にロードします。たとえば、LDS SI,[TBL1]とすると、TBL1で示した場所にある値(オフセット:セグメント)が、DSレジスタとSIレジスタにロードされます。他に、LESという命令がありますが、これは、DSのかわりにESにロードされます。
XLAT
「BXレジスタ+ALレジスタ」で示されたアドレスの値を、ALレジスタにセットします。たとえば、BXレジスタにバッファの先頭アドレスをセットしておいて、そこから、+ALの所にあるデーターを取り出したい時に使います。
LEA
アドレスをレジスタにセットします。たとえば、LEA BX,[SI]と書くと、SIレジスタの示すアドレスにある値ではなく、SIレジスタの値そのものがBXレジスタに入ります。また、LEA DI,[SI+BX]と書くと、DIレジスタには、SI+BXの結果そのものが入ります。
LDS
DSレジスタと、指定レジスタに値を同時にロードします。たとえば、LDS SI,[TBL1]とすると、TBL1で示した場所にある値(オフセット:セグメント)が、DSレジスタとSIレジスタにロードされます。他に、LESという命令がありますが、これは、DSのかわりにESにロードされます。
XLAT
「BXレジスタ+ALレジスタ」で示されたアドレスの値を、ALレジスタにセットします。たとえば、BXレジスタにバッファの先頭アドレスをセットしておいて、そこから、+ALの所にあるデーターを取り出したい時に使います。
MS-DOSに戻る
シングルタスクであるMS-DOS上でアセンブラでプログラムを作る場合、最後にはMS-DOSに制御を戻します。Linuxでは無限ループにしておいて常にバックグラウンドで動作させておいて、不要になったらKILL
-KILLコマンドでメモリから削除するという手もあるのですが、MS-DOSは基本的にシングルタスクなので、プログラムが終了したらMS-DOSに戻さないと、そのプログラムのせいでコンピューターをリセットせざるを得なくなります。(WindowsのDOS窓なら話は別ですが)
MOV AH,4CH
INT 21H
AHレジスタに4CHをいれておき、INT 21HのDOSコールをする事で、プログラムは終了し、DOSの制御に戻ります。
MOV AH,4CH
INT 21H
AHレジスタに4CHをいれておき、INT 21HのDOSコールをする事で、プログラムは終了し、DOSの制御に戻ります。
最後に
以上で、アセンブラの命令はほとんど説明し終わりました。アセンブラは命令数自体は非常に少なく、また、それらをすべて使わなくても、プログラムを作ることはできます。しかし、逆にいえば、これだけでは、何も作ることはできません。つまり、アセンブラでプログラムを作るためには、「どこのメモリを、どう書き換えると、何が起こるか」「どの割り込みを、どう呼べば、どうなるか」「どのI/Oポートを書き換えると、どうなるか」を調べなくてはなりません。
アセンブラでプログラムを作る場合は、まずその機械の資料を集めてみましょう。逆に目的のハードウェアの仕様書さえあれば、アセンブラ使いにとって鬼に金棒です。
アセンブラでプログラムを作る場合は、まずその機械の資料を集めてみましょう。逆に目的のハードウェアの仕様書さえあれば、アセンブラ使いにとって鬼に金棒です。
 このページの先頭へ
このページの先頭へ
広告