hexdump2
hexdump2とは
Linuxに標準で入っているhexdumpコマンドは2バイト単位で表示されるのですが、DOS形式に慣れてしまうと、なんかわかりにくいというか、違和感を覚えます。
このhexdump2コマンドは、16進ダンプリストをMS-DOSでおなじみの形式で出力します。また、漢字も正しく出力されます。もちろん、漢字コードが16バイト目と17バイト目に分かれてしまっても、正しく表示されます。
漢字コードはEUCコードとシフトJISコードを選択する事ができますが、日本語表記ができない端末のために、-nokanjiオプションも用意されています。
・出力結果

このhexdump2コマンドは、16進ダンプリストをMS-DOSでおなじみの形式で出力します。また、漢字も正しく出力されます。もちろん、漢字コードが16バイト目と17バイト目に分かれてしまっても、正しく表示されます。
漢字コードはEUCコードとシフトJISコードを選択する事ができますが、日本語表記ができない端末のために、-nokanjiオプションも用意されています。
・出力結果
作成方法
まず、下記リンクをクリックして、ソース一式をダウンロードします。
hexdump2-1.02.tar.gzをダウンロード
これを、適当なコンパイル用のディレクトリにアップします。
tar xvzf hexdump2-1.02.tar.gz
cd hexdump2-1.02
make
sudo make install
コンパイルが通れば、実行ファイルが/usr/local/binにコピーされます。外部ライブラリは使ってないので、configureスクリプトは入ってません。お使いの環境でコンパイルが通らない場合は、Makefileを書き換えてみてください。
このサイトで使っているサーバー(CentOS4.7)では正常にコンパイルする事ができましたが、全てのLinuxでコンパイルできるとは限りません。Linuxのディストリビューションによってはエラーが出てしまう事も考えられますが、その際は申し訳ありませんが、エラーの内容をチェックしてソースやMakefileの修正をお願いします。
hexdump2-1.02.tar.gzをダウンロード
これを、適当なコンパイル用のディレクトリにアップします。
tar xvzf hexdump2-1.02.tar.gz
cd hexdump2-1.02
make
sudo make install
コンパイルが通れば、実行ファイルが/usr/local/binにコピーされます。外部ライブラリは使ってないので、configureスクリプトは入ってません。お使いの環境でコンパイルが通らない場合は、Makefileを書き換えてみてください。
このサイトで使っているサーバー(CentOS4.7)では正常にコンパイルする事ができましたが、全てのLinuxでコンパイルできるとは限りません。Linuxのディストリビューションによってはエラーが出てしまう事も考えられますが、その際は申し訳ありませんが、エラーの内容をチェックしてソースやMakefileの修正をお願いします。
使い方
ソースが正しくコンパイルされていれば、実行ファイルhexdump2というファイルが作られていると思います。このファイルを実行します。
|
書式 hexdump2 [ファイル名] [オプション] [--help] ファイル名・・・入力ファイル名を指定します。指定しなかった時は、標準入力になります。 |
オプション
-o ファイル名
出力ファイルを指定します。指定しなかった時は、標準出力になります。-o の後にスペースで区切って、出力ファイル名を入れてください。
-euc
漢字コードをEUCコードとみなしてキャラクターコード欄にeucコードで出力します。なので、teratermやPoderosaは、EUCコードを表示するようにしておいてください。
-sjis
漢字コードをシフトJISコードとみなしてキャラクターコード欄にシフトJISコードで出力します。なので、teratermやPoderosaは、シフトJISコードを表示するようにしておいてください。
-nokanji
漢字コードは全てバイナリとみなし、キャラクターコード欄は点になります。マルチバイトを出力できない環境で指定すると便利です。
-offset オフセット値
-offsetに続いてスペースで区切ってオフセット値を指定します。 オフセット値は10進数で指定しますが、頭に0xをつけた場合は、16進数とみなします。 ファイルサイズより大きい値を指定するとエラーになります。
--help
ヘルプを出力します。 このようなコマンドラインで使うアプリは、なるべく多くの国の人が読めるように英語で書くか、少なくとも多国語対応で作る慣習があるのですが、 私が英語ができないせいで日本語(EUCコード)のヘルプしかありません。
出力ファイルを指定します。指定しなかった時は、標準出力になります。-o の後にスペースで区切って、出力ファイル名を入れてください。
-euc
漢字コードをEUCコードとみなしてキャラクターコード欄にeucコードで出力します。なので、teratermやPoderosaは、EUCコードを表示するようにしておいてください。
-sjis
漢字コードをシフトJISコードとみなしてキャラクターコード欄にシフトJISコードで出力します。なので、teratermやPoderosaは、シフトJISコードを表示するようにしておいてください。
-nokanji
漢字コードは全てバイナリとみなし、キャラクターコード欄は点になります。マルチバイトを出力できない環境で指定すると便利です。
-offset オフセット値
-offsetに続いてスペースで区切ってオフセット値を指定します。 オフセット値は10進数で指定しますが、頭に0xをつけた場合は、16進数とみなします。 ファイルサイズより大きい値を指定するとエラーになります。
--help
ヘルプを出力します。 このようなコマンドラインで使うアプリは、なるべく多くの国の人が読めるように英語で書くか、少なくとも多国語対応で作る慣習があるのですが、 私が英語ができないせいで日本語(EUCコード)のヘルプしかありません。
表示形式を指定するオプション
以下の表示形式を指定するオプションを使う事ができます。
無指定
何も指定しないと、MS-DOS形式で出力します。
-asm
アセンブラのソースに組み込みやすい形で出力します。
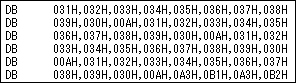
-basic
BASICのソースに組み込みやすい形で出力します。

-c
C系の言語(C、Perl、PHP)のソースに組み込みやすい形式で出力します。
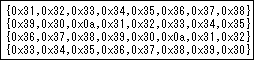
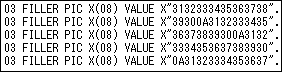
-cobol
COBOL言語のソースに組み込みやすい形式で出力します。03レベルのPIC文として出力します。 需要があるとは思えませんが・・・。
-plane
普通に16進数の並びとして出力します。PerlやPHPなどで、split(PHPならpreg_split)で分解するのに便利と思います。

・オプションを忘れた時は
このコマンドはオプションが色々あって「そんなの全部覚えてられないよー」という方は、--helpというコマンドだけ覚えておいてください。オプションの一覧と説明が表示されます。端末設定をEUCコードにしておいてください。
無指定
何も指定しないと、MS-DOS形式で出力します。
-asm
アセンブラのソースに組み込みやすい形で出力します。
-basic
BASICのソースに組み込みやすい形で出力します。
-c
C系の言語(C、Perl、PHP)のソースに組み込みやすい形式で出力します。
-cobol
COBOL言語のソースに組み込みやすい形式で出力します。03レベルのPIC文として出力します。 需要があるとは思えませんが・・・。
-plane
普通に16進数の並びとして出力します。PerlやPHPなどで、split(PHPならpreg_split)で分解するのに便利と思います。
・オプションを忘れた時は
このコマンドはオプションが色々あって「そんなの全部覚えてられないよー」という方は、--helpというコマンドだけ覚えておいてください。オプションの一覧と説明が表示されます。端末設定をEUCコードにしておいてください。
使用例
hexdump2 /etc/mail/access.db
hexdump2 < /etc/mail/access.db
hexdump2 < /etc/mail/access.db
/etc/mail/access.db を普通に16進ダンプします。上と下は同じ動作をしますが、下は標準入力からリダイレクトしています。
hexdump2 /etc/mail/access.db -o accessdb.dmp
hexdump2 /etc/mail/access.db > accessdb.dmp
hexdump2 /etc/mail/access.db > accessdb.dmp
/etc/mail/access.db を普通に16進ダンプし、結果をaccessdb.dmpというファイルに書きます。上と下は同じ動作をしますが、下は標準出力からリダイレクトしています。
hexdump2 /etc/mail/access.db -offset 16
hexdump2 /etc/mail/access.db -offset 0x10
hexdump2 /etc/mail/access.db -offset 0x10
/etc/mail/access.db を普通に16進ダンプします。ファイルを16バイト分進めてから、17バイト目から出力します。下の例は、オフセットを16進数で指定しています。
hexdump2 /etc/mail/access.db -asm > accessdb.asm
/etc/mail/access.db をアセンブラに組み込みやすい形で出力し、結果をaccessdb.asmというファイルに入れます。
制限事項
・オフセットを指定する場合の注意
offsetを指定する時に、オフセット値を16で割り切れない数を指定した時は、

図の赤斜線で示したように、隙間ができて、一番左のアドレスは必ず16で割り切れるアドレス(つまり、16進数で下一桁が0)になります。
また、offset値の指定がたまたま運悪く、漢字の下位バイト目から表示させてしまうと、右のキャラクター表示が化け化けになってしまいます。そうなった時は、offset値を±1してから再度実行してみてください。
・-sjisを指定する場合の注意
シフトJISコードのテキストを-sjisオプション付きで表示させると、文字化けせずに漢字が表示される・・・と思ったら化けてしまった、という場合、ターミナルの「端末設定」を確認してください。表示させるテキストと端末設定は一致している必要があります。
offsetを指定する時に、オフセット値を16で割り切れない数を指定した時は、
図の赤斜線で示したように、隙間ができて、一番左のアドレスは必ず16で割り切れるアドレス(つまり、16進数で下一桁が0)になります。
また、offset値の指定がたまたま運悪く、漢字の下位バイト目から表示させてしまうと、右のキャラクター表示が化け化けになってしまいます。そうなった時は、offset値を±1してから再度実行してみてください。
・-sjisを指定する場合の注意
シフトJISコードのテキストを-sjisオプション付きで表示させると、文字化けせずに漢字が表示される・・・と思ったら化けてしまった、という場合、ターミナルの「端末設定」を確認してください。表示させるテキストと端末設定は一致している必要があります。
最後に
MS-DOSを使っていた頃、アセンブラで便利コマンド集のようなものを作っていたのですが、いまいち使う人がほとんどいませんでした。最近、LinuxのCでMS-DOS用に作ったものを移植しているのですが、アセンブラに比べればかなり楽ですね。あの頃、Linuxをやっていれば、もっと使ってくれる人も多かったかもしれません。
このコマンドも、もっとバージョンアップさせていけばどこかのディストリビューションに入れてもらえるかも、と思ったのですが、 ヘルプが日本語で書いてあるようなコマンドをディストリビューションに標準で入れてもらえるわけないですね、やっぱ。
このコマンドも、もっとバージョンアップさせていけばどこかのディストリビューションに入れてもらえるかも、と思ったのですが、 ヘルプが日本語で書いてあるようなコマンドをディストリビューションに標準で入れてもらえるわけないですね、やっぱ。
 このページの先頭へ
このページの先頭へ
広告